Вопрос 10. Дискретные и интервальные ряды распределения и их графическое изображение. Дискретный вариационный ряд распределения
АНАЛИЗ РЯДОВ РАСПРЕДЕЛЕНИЯ, Понятие статистические ряды распределения
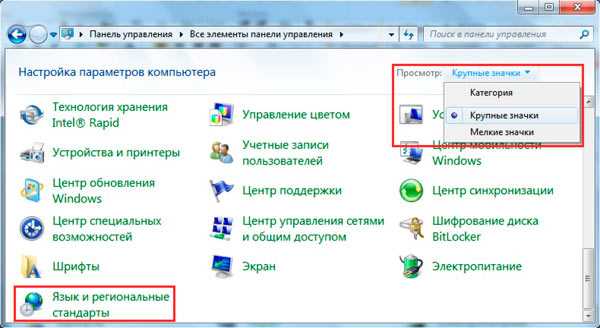
§ 51 Понятие статистические ряды распределения
Располагая данные статистического наблюдения, характеризующих то или иное явление, прежде всего необходимо их упорядочить, т.е. придать характер системности
Английский статистик. УДжРейхман по поводу неупорядоченных совокупностей образно сказал, что столкнуться с массой необобщенных данных равнозначно ситуации, когда человека бросают в лесной чаще без компаса. Что же собой представляет систематизация статистических данных в виде рядов распределениялу?
Статистический ряд распределения - это упорядоченные статистические совокупности (табл. 17). Простейшим видом статистического ряда распределения ранжированном ряд, т.е. ряд чисел, находящейся в порядке возрастания ч или падения варьируя признаки. Такой ряд не позволяет судить о закономерности, заложенные в распределенных данных: у какой величины группируется большинство показателей, какие есть отклонения от этой величины; как а общая картина распределения. С этой целью группируют данные, показывая, как часто встречаются отдельные наблюдения в общем их числе (Схема 1а 1).
. Таблица 17
. Общий вид статистических рядов распределения
. Схема 1. Схемастатистичних рядов распределения
Распределение единиц совокупности по признакам, не имеют количественного выражения, называется атрибутивным рядом (например, распределение предприятий по их производственным направлением)
Ряды распределения единиц совокупности по признакам, имеют количественное выражение, называются вариационными рядами. В таких рядах значение признака (варианты) находятся в порядке возрастания или убывания
В вариационном ряде распределения различают два элемента: варианта и частота. Варианта - это отдельное значение группировочного признаки частота - число, которое показывает, сколько раз встречается каждый варианта
В математической статистике исчисляется еще один элемент вариационного ряда - частисть. Последняя определяется как отношение частоты случаев данного интервала к общей сумме частот частисть определяется в долях единицы, процентах (%) в промилле (% о)
Таким образом, вариационный ряд распределения - это такой ряд, в котором варианты расположены в порядке возрастания или убывания, указаны их частоты или частости. Вариационные ряды бывают дискретные (переривни) и др. нтервальни (непрерывного).
. Дискретные вариационные ряды - это такие ряды распределения, в которых варианта как величина количественного признака может принимать только определенное значение. Варианты различаются между собой на одну или несколько единиц
Так, количество произведенных деталей за смену конкретным рабочим может выражаться только одним определенным числом (6, 10, 12 и тд). Примером дискретного вариационного ряда может быть распределение работников по к количеством произведенных деталей (табл 18 18).
. Таблица 18
. Дискретный ряд распределения_
| Сделано деталей за смену, шт (х) | Количество рабочих чел, () |
| 6 | 16 |
| 7 | 10 |
| 8 | 8 |
| 9 | 10 |
| 10 | 12 |
| 11 | 16 |
| 12 | 3 |
. Интервальные (непрерывного) вариационные ряды - такие ряды распределения, в которых значение варианты даны в виде интервалов, т.е. значения признаков могут отличаться друг от друга на сколь угодно малую величину. При построении вариационного ряда нэп переривнои признаки невозможно указать каждое значение варианты, поэтому совокупность распределяется по интервалам. Последние могут быть равны и неравны. Для каждого из них указываются частоты или частости (табл. 1 9 19).
В интервальных рядах распределения с неравными интервалами вычисляют такие математические характеристики, как плотность распределения и относительная плотность распределения на данном интервале. Первая характеристика определи ся отношением частоты до величины того же интервала, вторая - отношением частости к величине того же интервала. Для приведенного выше примера плотность распределения на первом интервале составит 3: 5 = 0,6, а относительная плотность на этом интервале - 7,5:5 = 1,55%.
. Таблица 19
. Интервальный ряд распределения _
| Численность работающих, чел (х) | Количество цехов (",) | % к итогу |
| 20-25 | 3 | 7,5 |
| 25-30 | 9 | 22,5 |
| 30-35 | 16 | 40,0 |
| 35-40 | 8 | 20,0 |
| 40-45 | 4 | 10,0 |
| Всего | 40 | 100,0 |
uchebnikirus.com
Понятие рядов распределения. Дискретные и интервальные ряды распределения
1.
2. Понятие рядов распределения. Дискретные и интервальные ряды распределения
Рядами распределения называются группировки особого вида, при которых по каждому признаку, группе признаков или классу признаков известны численность единиц в группе либо удельный вес этой численности в общем итоге. Т.е. ряд распределения – упорядоченная совокупность значений признака, расположенных в порядке возрастания или убывания с соответствующими им весами. Ряды распределения могут быть построены или по количественному, или по атрибутивному признаку.
Ряды распределения, построенные по количественному признаку, называются вариационными рядами. Они бывают дискретные и интервальные . Ряд распределения может быть построен по не прерывно варьирующему признаку (когда признак может принимать любые значения в рамках какого-либо интервала) и по дискретно варьирующему признаку (принимает строго определенные целочисленные значения).
Дискретным вариационным рядом распределения называется ранжированная совокупность вариантов с соответствующими им частотами или частностями. Варианты дискретного ряда – это дискретно прерывно изменяющиеся значения признак, обычно это результат подсчета.
Дискретные
вариационные ряды строят обычно в том случае, если значения изучаемого признака могут отличаться друг от друга не менее чем на некоторую конечную величину. В дискретных рядах задаются точечные значения признака. Пример : Распределение мужских костюмов, реализованных магазинами за месяц по размерам.Пример : Распределение покупок в продуктовом магазине по сумме.
Если в дискретных вариационных рядах частотная характеристика относится непосредственно к варианту ряда, то в интервальных к группе вариантов.
Ряды распределения удобно анализировать при помощи их графического изображения, позволяющего судить и о форме распределения, о закономерностях. Дискретный ряд изображается на графике в виде ломаной линии – полигона распределения . Для его построения в прямоугольной системе координат по оси абсцисс в одинаковом масштабе откладываются ранжированные (упорядоченные) значения варьирующего признака, а по оси ординат наносится шкала для выражения частот.
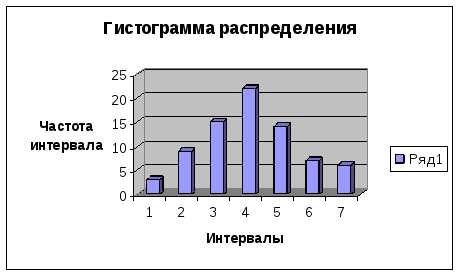
Интервальные ряды изображаются в виде гистограмм распределения (то есть столбиков диаграмм).
При построении гистограммы на оси абсцисс откладываются величины интервалов, а частоты изображаются прямоугольниками, построенными на соответствующих интервалах. Высота столбиков в случае равных интервалов должна быть пропорциональна частотам.
Любая гистограмма может быть преобразована в полигон распределений, для этого необходимо соединить между собой отрезками прямой вершины ее прямоугольников.
2. Индексный метод анализа влияния средней выработки и среднесписочной численности на изменения объема продукции
Индексный метод применяется для анализа динамики и сравнения обобщающих показателей, а так же факторов, влияющих на изменение уровней этих показателей. С помощью индексов можно выявить влияние средней выработки и среднесписочной численности на изменения объема продукции. Эта задача решается путем построения системы аналитических индексов.
Индекс объема продукции с индексом среднесписочной численности работающих и индексом средней выработки связан таким же образом, как объем производства (Q) связан с выработкой (w) и численностью (r) .
Q = w·r, где Q – объем продукции,
w - средняя выработка,
r – среднесписочная численность.
Как видно, речь идет о взаимосвязи явлений в статике: произведение двух факторов дает общий объем результативного явления. Очевидно также, что эта связь функциональная, следовательно, динамика этой связи изучается с помощью индексов. Для приведенного примера это следующая система:
Jw × Jr = Jwr .
Например, индекс объема продукции Jwr, как индекс результативного явления, можно разложить на два индекса-фактора: индекс средней выработки (Jw), и индекс среднесписочной численности (Jr):
↓ ↓ ↓
Индекс Индекс Индекс
объема средней среднесписочной
продукции выработки численности
где J w - индекс производительности труда, рассчитываемый по формуле Ласпейреса;
Jr - индекс численности работающих, рассчитываемый по формуле Пааше.
Индексные системы используются для определения влияния отдельных факторов на формирование уровня результативного показателя, позволяют по 2-м известным значениям индексов определить значение неизвестного.
На базе приведенной системы индексов можно найти и абсолютный прирост объема продукции, разложенный на влияние факторов.
1. Общий прирост объема продукции:
∆wr = ∑w1 r1 - ∑w0 r0 .
2. Прирост за счет действия показателя средней выработки:
∆wr/w = ∑w1 r1 - ∑w0 r1 .
3. Прирост за счет действия показателя среднесписочной численности:
∆wr/r = ∑w0 r1 - ∑w0 r0
∆wr = ∆wr/w + ∆wr/r.
Пример. Известны следующие данные
Мы можем определить, как изменился объем продукции в относительном и абсолютном выражении и как отдельные факторы повлияли на это изменение.
Объем продукции составил:
в базисном периоде
w0 * r0 = 2000 * 90 = 180000,
а в отчетном
w1 * r1 = 2100 * 100 = 210000.
Следовательно, объем продукции увеличился на 30000 или на 1,16%.
∆wr=∑w1 r1 -∑w0 r0= (210000-180000)=30000
или (210000:180000)*100%=1,16%.
Данное изменение объема продукции было обусловлено:
1) увеличением среднесписочной численности на 10 человек или на 111,1%
r1 /r0 = 100 / 90 = 1,11 или 111,1%.
В абсолютном выражении за счет этого фактора объем продукции увеличился на 20000:
w0 r1 – w0 r0 = w0 (r1 -r0 ) = 2000 (100-90) = 20000.
2) увеличением средней выработки на 105% или на 10000:
w1 r1 /w0 r1 = 2100*100/2000*100 = 1,05 или 105%.
В абсолютном выражении прирост составляет:
w1 r1 – w0 r1 = (w1 -w0 )r1 = (2100-2000)*100 = 10000.
Отсюда, совместное влияние факторов составило:
1. В абсолютном выражении
10000 + 20000 = 30000
2. В относительном выражении
1,11 * 1,05 = 1,16 (116%)
Следовательно, прирост составляет 1,16%. Оба результата были получены ранее.
3. Индексы постоянного состава. Принципы построения
Слово «index» в переводе означает указатель, показатель. В статистике индекс трактуется как относительный показатель, характеризующий изменение явления во времени, пространстве или по сравнению с планом. Поскольку индекс относительная величина, наименования индексов созвучны с наименованием относительных величин.
В тех случаях, когда мы анализируем изменение во времени сравниваемой продукции, мы можем поставить вопрос о том, как в различных условиях (на различных участках) меняются составляющие индекса (цена, физический объем, структура производства или реализации отдельных видов продукции). В связи с этим строятся индексы постоянного состава, переменного состава, структурных сдвигов.
Индекс постоянного (фиксированного) состава – это индекс, который характеризует динамику средней величины при одной и той же фиксированной структуре совокупности.
Принцип построения индекса постоянного состава – элиминировать влияние изменений в структуре весов на индексируемую величину путем расчета средневзвешенного уровня индексируемого показателя с одними и теми же весами.
Индекс постоянного состава по своей форме тождественен агрегатному индексу. Агрегатная форма является наиболее распространенной.
Индекс постоянного состава исчисляется с весами, зафиксированными на уровне одного какого-либо периода, и показывает изменение только индексируемой величины. Индекс постоянного состава элиминирует влияние изменений в структуре весов на индексируемую величину путем расчета средневзвешенного уровня индексируемого показателя с одними и теми же весами. В индексах постоянного состава сопоставляются показатели, рассчитанные на базе неизменной структуры явлений.
mirznanii.com
2.2.2 Интервальный вариационный ряд распределения
Каждое значение непрерывного признака как правило имеет частоту встречаемости равную 1, поэтому построение вариационного ряда по типу дискретного ряда здесь невозможно. Для непрерывного признака строится интервальный вариационный ряд. Интервальный вариационный ряд может быть построен также и по дискретному признаку в том случае если он принимает значения в очень широком диапазоне ( например число жителей в населенном пункте может изменяться от 1-го до нескольких миллионов ). В интервальном вариационном ряду в левой колонке таблицы вместо отдельных значений записываются их интервалы, а в правой – вместо частот для отдельных значений признака записываются частоты интервалов, то есть сколько единиц имеют значения признака в пределах того или иного интервала. Следовательно, макет интервального вариационного ряда выглядит так :
Таблица 2.2.2
Интервальный вариационный ряд распределения …………
| Интервалы значений признака | Частота Частота интервала ( |
| от до | |
| от до | |
| …………… | |
| Итого | Сумма частот ( |

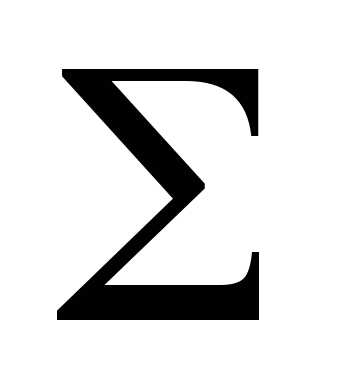
 )
)Построение интервального ряда распределения включает в себя несколько этапов.
На первом этапе определяется число интервалов ( групп ) на которое подразделяется совокупность. Наиболее часто используемыми формулами для определения числа интервалов являются две : 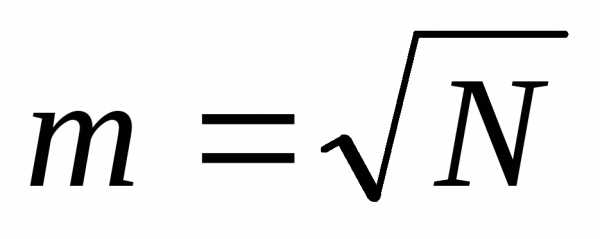 и, где
и, где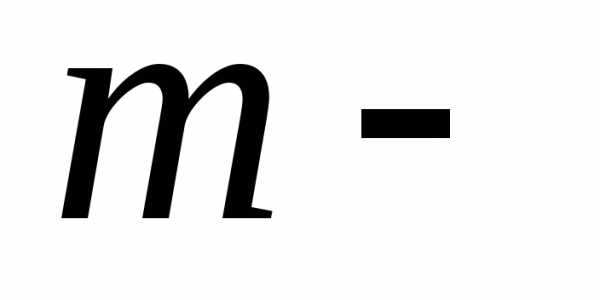 число интервалов . а
число интервалов . а - общая численность совокупности. Эти формулы дают схожую оценку числа интервалов при общей численности совокупности примерно до 50 единиц. При большей совокупности обнаруживаются большие различия. Например, приN = 100, по первой формуле число интервалов равно 10, а по второй -7, при N =1000 соответственно 32 и 10. и предпочтение следует отдавать второй формуле.
- общая численность совокупности. Эти формулы дают схожую оценку числа интервалов при общей численности совокупности примерно до 50 единиц. При большей совокупности обнаруживаются большие различия. Например, приN = 100, по первой формуле число интервалов равно 10, а по второй -7, при N =1000 соответственно 32 и 10. и предпочтение следует отдавать второй формуле.
Любой интервал содержит нижнюю и верхнюю границы На втором этапе следует рассчитать шаг интервала., то есть разницу между этими границами . Эта разница для всех интервалов должна быть одинаковой. Для расчета шага интервала обычно используется формула : 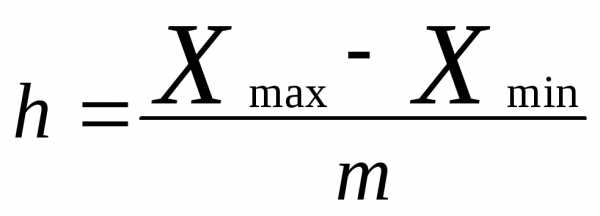 , где
, где - искомый шаг интервала ;
- искомый шаг интервала ; - максимальное в совокупности значение признака ;
- максимальное в совокупности значение признака ; - минимальное в совокупности значение признака ;
- минимальное в совокупности значение признака ; число интервалов. Если при изучении ранжированного ряда обнаружится, что максимальное или минимальное ( или даже несколько значений ) сильно отличаются от остальных, то при расчете шага интервала следует использовать соответственно не максимальное, а предшествующее ему значение, не минимальное , а следующее в ранжированном ряду значение признака. В противном случае может получиться , что в одном- двух интервалах будут сосредоточены все наблюдения.
число интервалов. Если при изучении ранжированного ряда обнаружится, что максимальное или минимальное ( или даже несколько значений ) сильно отличаются от остальных, то при расчете шага интервала следует использовать соответственно не максимальное, а предшествующее ему значение, не минимальное , а следующее в ранжированном ряду значение признака. В противном случае может получиться , что в одном- двух интервалах будут сосредоточены все наблюдения.
Шаг интервала обычно рассчитывают с той же точностью с какой представлены значения признака в изучаемой совокупности. Иногда шаг интервала берут с точностью на один знак меньше той , какая имеет место в исходной совокупности. Если при расчете шага интервала требуется округление до заданной точности , то округление производят всегда в большую сторону.
После определения шага интервала следует найти границы интервалов : первый интервал в качестве нижней границы имеет  , в качестве верхней
, в качестве верхней +
+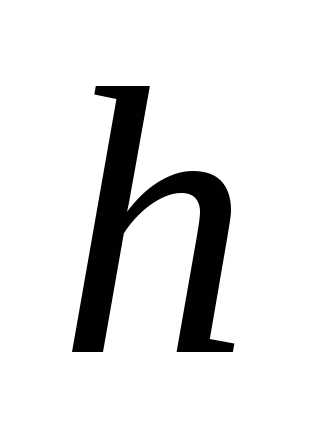 ; второй интервал в качестве нижней имеет верхнюю границу первого интервала ,то есть
; второй интервал в качестве нижней имеет верхнюю границу первого интервала ,то есть +
+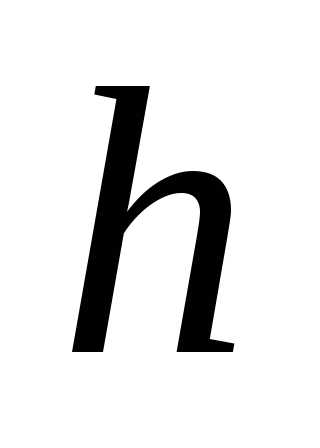 , для получения верхней границы этого интервала надо вновь прибавить шаг интервала , то есть
, для получения верхней границы этого интервала надо вновь прибавить шаг интервала , то есть +,+
+,+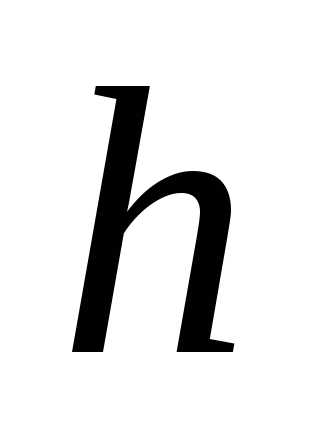 =
=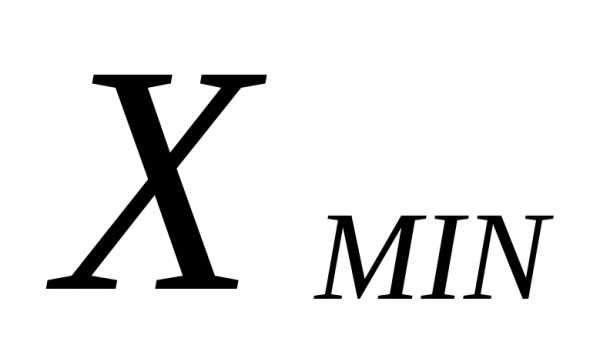 + 2
+ 2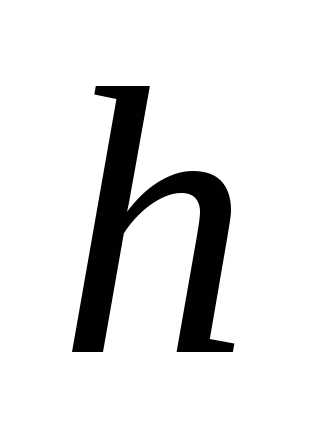 и так далее. Если при определении шага интервала пришлось отказаться от
и так далее. Если при определении шага интервала пришлось отказаться от , то в первом интервале сразу находится верхняя граница, для чего к значению, которое использовалось при расчете шага интервала следует прибавить шаг интервала, нижняя граница первого интервала не обозначается . Сам интервал будет открыт снизу. Если при расчете шага интервала пришлось отказаться от максимального значения, для того , чтобы и это значение присутствовало в интервальном ряду, открытым сверху делают последний интервал. Определив границы интервалов, далее следует подсчитать сколько единиц попало в каждый интервал. Для этого удобнее всего воспользоваться ранжированным рядом, обозначив на нем границы интервалов. Если единица имеет значение признака на границе интервала, то она может вой- ти только в один интервал ; в какой именно решает сам исследователь – в нижний ( принцип включительно) или верхний ( принцип исключительно ). Результаты подсчетов оформляются в таблице, представленной ранее на макете. Графически интервальный вариационный ряд отображается в виде гистограммы распределения, при этом на оси абсцисс откладываются интервалы, а на оси ординат - частоты интервалов Вид такого графика следующий
, то в первом интервале сразу находится верхняя граница, для чего к значению, которое использовалось при расчете шага интервала следует прибавить шаг интервала, нижняя граница первого интервала не обозначается . Сам интервал будет открыт снизу. Если при расчете шага интервала пришлось отказаться от максимального значения, для того , чтобы и это значение присутствовало в интервальном ряду, открытым сверху делают последний интервал. Определив границы интервалов, далее следует подсчитать сколько единиц попало в каждый интервал. Для этого удобнее всего воспользоваться ранжированным рядом, обозначив на нем границы интервалов. Если единица имеет значение признака на границе интервала, то она может вой- ти только в один интервал ; в какой именно решает сам исследователь – в нижний ( принцип включительно) или верхний ( принцип исключительно ). Результаты подсчетов оформляются в таблице, представленной ранее на макете. Графически интервальный вариационный ряд отображается в виде гистограммы распределения, при этом на оси абсцисс откладываются интервалы, а на оси ординат - частоты интервалов Вид такого графика следующий
studfiles.net
Ряды распределения в статистике
Построение рядов распределения
Наиболее простым способом обобщения статистического материала является построение рядов. Результатом сводки статистического исследования могут быть ряды распределения.
После определения группировочного признака, количества групп и интервалов группировки данные сводки и группировки представляются в виде рядов распределения и оформляются в виде статистических таблиц.
Ряд распределния является одним из видов группировок.
Рядом распределения в статистике называется упорядоченное распределение единиц совокупности на группы по какому-либо одному признаку: по качественному или количественному.
Виды рядов распределения
В зависимости от признака, положенного в основу образования ряда распределения различают атрибутивные и вариационные ряды распределения:
атрибутивными называют ряды распределения, построенные по качественными признакам;
вариационными называют ряды распределения, построенные в порядке возрастания или убывания значений количественного признака.
Вариационный ряд распределения состоит из двух столбцов. В первом столбце приводятся количественные значения варьирующегося признака, которые называются вариантами и обозначаются . Дискретная варианта — выражается целым числом. Интервальная варианта находится в пределах от и до. В зависимости от типа варианты можно построить дискретный или интервальный вариационный ряд. Во втором столбце содержится количество конкретных вариант, выраженное через частоты или частости:
частоты — это абсолютные числа, показывающие столько раз в совокупности встречается данное значение признака; сумма всех частот должна быть равна численности единиц всей совокупности;
частости — это частоты выраженные в процентах к итогу; сумма всех частостей выраженных в процентах должна быть равна 100% в долях единице.
Вариационный ряд характеризуется двумя элементами: вариантой (Х) и частотой (f). Варианта – это отдельное значение признака отдельной единицы или группы совокупности. Число, показывающее, сколько раз встречается то или иное значение признака, называется частотой. Если частота выражена относительным числом, то она называется частостью.
Вариационный ряд может быть:
интервальным, когда определены границы «от» и «до», интервальные ряды распределения можно представить графически в виде гистограммы;
Графическое изображение рядов распределения
Наглядно ряды распределения представляются при помощи графических изображений.
Ряды распределения изображаются в виде:
полигона;
гистограммы;
кумуляты;
огивы.
При построении полигона на горизонтальной оси (ось абсцисс) откладывают значения варьирующего признака, а на вертикальной оси (ось ординат) — частоты или частости.
Для построения гистограммы по оси абсцисс указывают значения границ интервалов и на их основании строят прямоугольники, высота которых пропорциональна частотам (или частостям).
Распределение признака в вариационном ряду по накопленным частотам (частостям) изображается с помощью кумуляты.
Кумулята или кумулятивная кривая в отличие от полигона строится по накопленным частотам или частостям. При этом на оси абсцисс помещают значения признака, а на оси ординат — накопленные частоты или частости.
Огива строится аналогично кумуляте с той лишь разницей, что накопленные частоты помещают на оси абсцисс, а значения признака — на оси ординат.
Разновидностью кумуляты является кривая концентрации или график Лоренца. Для построения кривой концентрации на обе оси прямоугольной системы координат наносится масштабная шкала в процентах от 0 до 100. При этом на оси абсцисс указывают накопленные частости, а на оси ординат — накопленные значения доли (в процентах) по объему признака.
studfiles.net
Вопрос 10. Дискретные и интервальные ряды распределения и их графическое изображение
дискретные, - значения признака выражены в виде изолированных величин (чаще целых),
и интервальные (непрерывные) - в которых значения признака заданы определенным интервалом. (участники ВЭД по товарообороту: от 1000 до 10000 долл., от 10000 до 20000 долл..
Статистическое распределение дискретного вариационного ряда- это перечень вариант в возрастающем порядке и соответствующих им частот (относительных частот).
Статистическое распределение непрерывного вариационного ряда- это последовательность интервалов в возрастающем порядке и соответствующих им частот (в качестве частоты, соответствующей интервалу, принимают сумму частот вариант, попавших в этот интервал).
Способы построения и представления вариационных интервальных рядов.Интервалы подбираются так, чтобы ряд распределения дал более подробную, но обозримую структуру статистической совокупности.
Интервалы бывают равные и неравные:
· Равные применяют в случаях, когда показатель изменяется в незначительных пределах.
· Неравные - в остальных случаях.
Величина равных интервалов вычисляется по формуле:
, (5.1)
где xmax, xmin - максимальное и минимальное значения показателя, соответственно;
k - число интервалов.
Если не решен вопрос о количестве интервалов, то его рассчитывают по формуле, предложенной американским ученым Стеджерссом:
k= [1 + 3,222 lg (N)], где N - кол-во рассматриваемых показателей (объем совокупности),
Часто для расчета статистических показателей от непрерывного (интервального) ряда удобно перейти к дискретному. Для этого в качестве дискретных значений ряда берут середины частичных интервалов, а в качестве частот принимают сумму частот вариант, попавших в соответствующий интервал.
Для наглядности строят различные графические изображения статистического распределения.
Полигон частот (относительных частот) –это ломаная, вершинами которой являются точки (x1,f1),…, (xk ,fk) ((x1,fw1),…, (xk ,wk)), где x1,…, xk – варианты дискретного вариационного ряда, а f1,…,fk (w1,…,wk) – соответствующие частоты, выраженные в абсолютных единицах (относительные частоты, т.е. выраженные в %).
Для графического изображения интервального вариационного ряда используют гистограмму. При ее построении на оси абсцисс откладывают интервалы ряда, высота которых равна частотам (частостям), отложенным по оси ординат.
Вопрос 11. Статистическая таблица и ее элементы
Результаты статистических сводок и группировок чаще всего представляются в виде статистических таблиц.
Статистической таблицей называют форму наглядного изображения статистических данных о явлениях и процессах, присущих тем или иным сторонам общественной жизни.
Таблица представляет собой ряд пересекающихся горизонтальных и вертикальных линий, образующих по горизонтали строки, а по вертикали – графы (столбцы, колонки), которые в совокупности составляют скелет таблицы. Таблицу можно представить как простое предложение, где подлежащим является то, о чем идет речь в таблице, либо единица наблюдения, либо группа единиц совокупности, которые характеризуются цифровыми данными. могут быть предприятия, территории, виды продукции и т.п., а также группы или части.. Сказуемым таблицы называются числовые показатели, с помощью которых изучается объект, т.е. характеризующие подлежащее.
Таблица в зависимости от конструкции подлежащего бывают простые, групповые, комбинированные.
Простые - таблицы, содержащие перечень единиц стат. совокупности (либо хронологических дат).
Групповые - таблицы, подлежащее которых содержит группировку ед. наблюдения исходя из какого-либо одного признака.
Комбинационные (комбинированные) - таблицы, подлежащее которых содержит группировки единиц наблюдения не по одному, а по нескольким признакам.
Статистические таблицы являются не только формой наглядного и компактного изложения исходной информации, но и инструментом ее анализа, позволяют сопоставлять исходные данные, устанавливать взаимосвязь, выявлять закономерности изучаемых явлений.
Вопрос 12. Построение групповых и комбинационных таблиц
В зависимости от построения (разработки) подлежащего статистические таблицы подразделяются на три группы: простые, групповые, комбинационные.
Простые таблицы содержат перечень отдельных единиц, входящих в состав совокупности анализируемого экономического явления.
В групповых таблицах цифровая информация в разрезе отдельных составных частей исследуемой совокупности данных объединяется в определенные группы в соответствии с каким-либо признаком.
Комбинированные таблицы содержат отдельные группы и подгруппы, на которые подразделяются экономические показатели, характеризующие изучаемое экономическое явление. При этом такое подразделение осуществляется не по одному, а по нескольким признакам. в групповых таблицах осуществляется простая группировка показателей, а в комбинированных — комбинированная группировка. Простые таблицы вообще не содержат никакой группировки показателей. Последний вид таблиц содержит лишь несгруппированный набор сведений об анализируемом экономическом явлении.
Простые таблицы
Простые таблицы имеют в подлежащем перечень единиц совокупности, времени или территорий.
Групповые таблицы
Групповыми называются таблицы, имеющие в подлежащем группировку единиц совокупности по одному признаку.
Комбинационные таблицы
Комбинационные таблицы имеют в подлежащем группировку единиц совокупности по двум или более признакам.
По характеру разработки показателей сказуемого различают:
§ таблицы с простой разработкой показателей сказуемого, в которых имеет место параллельное расположение показателей сказуемого.
§ таблицы со сложной разработкой показателей сказуемого, в которых имеет место комбинирование показателей сказуемого: внутри групп, образованных по одному признаку, выделяют подгруппы по другому признаку.
Для достижения наибольшей выразительности статистической таблицы необходимо при ее оформлении придерживаться определенных правил
1 Форма статистической таблицы должна быть согласована с ранее существующими таблицами для обеспечения возможности сравнения данных за ряд отрезков времени
2 Название таблицы (общий заголовок) должна кратко и точно характеризовать основное ее содержание Это требование в равной степени касается и названий подлежащего и сказуемого таблицы Если общий заголовок недостаточно подробно сформулирован, то можно сделать примечания к нему.
3 В таблице должно быть указано, какой территории или какого периода или момента времени к приведенные данные, а также характер этих данных (фактич,норматив.,расчетные и т д.).
4 Показатели таблицы должны иметь единицы измерения
5 Все числовые значения данного показателя отмечаются с одинаковой точностью и др.
infopedia.su
Дискретный ряд распределения.
Тема:27 Применение ЭВМ для обработки медико-биологической информации. Основные статистические характеристики дискретного статистического ряда распределения.
1. Цель занятия: Изучить основные понятия теории вероятности, дискретные случайные величины, способы задания, числовые характеристики дискретной случайной величины.
2. Основные вопросы темы:
1. Статистика
2. Математическая статистика
3. Непрерывные и дискретные случайные величины.
4. Вероятность события?
5. Частота события.
4. Условие нормировки вероятности.
5. Генеральная совокупность и выборка.
6. Закон распределения дискретной случайной величины.
7. Дискретный статистический ряд распределения.
8. Вариационный ряд.
9. Числовые характеристики дискретного статистического распределения: выборочное среднее, выборочная дисперсия, среднее квадратическое отклонение, мода, медиана.
10. Полигон частот и относительных частот, кумулята, огнива.
Краткая теория
1. Статистика – это наука, изучающая методы обработки результатов наблюдений массовых случайных явлений, обладающих закономерностью с целью выявления этих закономерностей. (это наука о методах изучения массовых явлениях).
2. Задачи статистики: изучение структуры взаимосвязей и динамики массовых явлений. Статистика исследует не отдельные факты, а массовые явления и процессы, выступающие как множество факторов, обладают как индивидуальными так и общими признаками.
3. Математическая статистика – наука изучающая, методы сбора и обработки числовых данных для повышения эффективности их интерпретации.
1. Случайной называют величину, которая в результате опыта может
принять то или иное значение в зависимости от различных случайных обстоятельств.
Например: число вызовов врача на дом, число заболевших гриппом за месяц, скорость ветра в момент замера.
Случайные величины обозначаются заглавными буквами латинского алфавит А, В, С,…….Х, Y. Изучение случайных величин является предметом статистических исследований.
Случайные величины можно разделить на дискретные и непрерывные.
2.. Случайная величина называется дискретной (прерывной), если она принимает некоторые определенные числовые значения, число значений которой счетное. Например: число зерен в колосе, количество студентов на лекции.
Задать дискретную случайную величину можно с помощью таблицы, в которой перечислены все возможные значения случайной величины и соответствующие им вероятности
3. Непрерывные случайные величины принимают любые значения внутри некоторого интервала. Например: температура тела человека, давление крови, вес тела и.т.д.
4.. Количественной оценкой возможности появления данного случайного события является вероятность.
Если в nопытах данная случайная величина m раз приняла определенное значение, то величина ν = m/n называется статистической вероятностью или частотой данного события.
Количественной оценкой возможности появления данного случайного события является вероятность.
Классической вероятностью Р(А) события А называется отношение числа исходов m, благоприятствующих наступлению ожидаемого события А, к числу всех возможных в данном испытании исходов n. P(А)=m/n.
Вероятность любого события А подчиняется условию нормировки:
0≤Р(А)≤1.
В математической статистике изучение случайной величины связано с выполнением ряда независимых опытов, в которых она принимает определенные значения. Полученные значения случайной величины представляют собой простую статистическую совокупность или простой статистический ряд.
5. Статистическая совокупность - это множество объектов, отличающихся друг от друга, но сходных относительно некоторого качественного или количественного признака, характеризующего эти объекты.
Пример: серия таблеток лекарственного вещества. Качественный признак-стандартность таблетки. Количественный признак – контролируемая масса таблеток.
Каждый отдельный элемент,входящий в совокупность, называется членом статистической совокупности.
Общее число членов совокупности называется ее объемом(N).
Если у данной статистической совокупности изучается некоторый признак, который изменяется при переходе от одного члена совокупности к другому, то изменение этого признака называется вариацией.
Значение признака у данного члена статистической совокупности называется его вариантой.
Бесконечно большая группа всех членов, которые могут быть к ней отнесены к данной совокупности, называется генеральной.
Множество объектов, случайно отобранных из генеральной совокупности, называется выборочной совокупностью или выборкой.
Число объектов выборки называется ее объемом (n).
Выборка должна достаточно хорошо отражать свойства генеральной совокупности, должна быть репрезентативной (представительной).
Набор значений случайной величины Х, полученных в результате nопытов, обозначают Х1, Х2,…..Хi .
Вероятности случайных величин обозначаются Р(Х1)=Р1, Р(Х2)=Р2………
6. Законом распределения случайной величины называется всякое соотношение, устанавливающее связь между возможными значениями случайной величины Xi и соответствующими им вероятностями Pi того, что случайная величина Х принимает значение Xi.
Закон распределения случайной величины может быть задан:
рядом распределения, функцией распределения и кривой распределения (для непрерывных величин).
Дискретный ряд распределения.
Таблица, содержащая значения вариант и их частоты или относительной частоты, называется статистическим дискретным рядом распределения или статистическим распределением выборки.
Последовательность вариант, записанная в возрастающем порядке называется вариационным рядом.
Вариационный ряд называется ранжированным, если варианты его расположен в определенном порядке по возрастающим или убывающим значениям.
Ряд может быть построен как по дискретному, так и по непрерывному признаку.
Чтобы задать дискретную случайную величину надо перечислить ее возможные значения и вероятности, с которыми они достигаются.
Пусть из генеральной совокупности извлечена выборка объемом n. Количественное значение изучаемого признака
Х1 - появилось m1 раз,
Х2 - появилось m2 раз
Х3 - появилось m3 раз,
Х4 - появилось m4 раз,
………………………
Хк - появилось mк раз,
Числа m1, m2, m3, m4, m5…. mк - называются частотами, их отношение к объему n выборки – относительными частотами.
Таблица 1.1
| Х | X1 | X2 | X3 | Xk | ||
| m | m1 | m2 | m3 | mk | ||
| P1 | P2 | P3 | Pk |
Построенная таблица называется законом распределения дискретной случайной величины или дискретным вариационным рядом.
Пример 1:
В результате отдельных испытаний активности тетрациклина гидрохлорида получены значения Хi( в ЕD/мг): 925,940,760,905, 995, 965, 940, 925, 940, 940, 905. Построить дискретный вариационный ряд.[3]
| Хi | ||||||
| Частота - n | ||||||
| Относительная Частота Рi | 0,1 | 0,2 | 0,2 | 0,3 | 0,1 | 0,1 |
Сумма относительных частот должна быть ∑Pi= 1
0,1+0,2+0,2+0,3+0,1+0,1= 1
Для графического изображения статистического распределения дискретного ряда используются полигон, кумуляту, огиву, интервального ряда- гистограммы.
Полигон.
Для построения полигона на оси Ох откладывают значения вариант Х, на оси Оу – значения частот m( или относительных частот- рi). Построенную таким образом ломаную линию, отрезки которой соединяют точки (Xi;mi) или (Хi;pi) называют полигоном частот (относительных частот).
(рис 1.1,1.2).
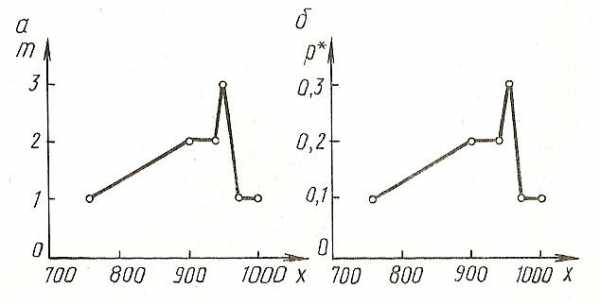
Рис.1.1 Полигон частот Рис.1.2 Полигон частот относительных частот
Для построения кумулятыпо оси абсцисс откладываются значения вариант, а по оси ординат – накопленные частоты. Соединяя затем соответствующие точки в системе координат, получается график, называемый кумулятой (пример 2).
Накопленные частотыполучаются последовательным суммированием или кумуляцией (от лат. Cumulo- накапливаю) частот в направлении от минимальной варианты до конца вариационного ряда.Полный ряд накопленных частот обозначается через S (пример3).
Если ряд накопленных частот нанести на ось абсцисс, а значения вариант расположить по оси ординат и построить график, получаетсяогива. Огива есть не что иное как кумулята, перевернутая на 1800.[5]
Пример 2
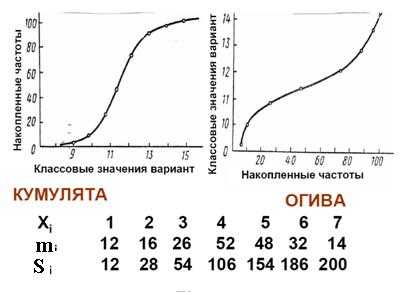
Пример 3 (Si- накопленные частоты)
8.Закон распределения полностью описывает дискретную случайную величину. Однако во многих случаях он неизвестен или достаточно бывает указать отдельные числа, выражающие в сжатой форме наиболее существенные особенности распределения. Эти числа называются числовыми характеристиками случайной величины.
Числовые характеристики дискретного статистического распределения: выборочное среднее, взвешенная средняя арифметическая, математическое ожидание, выборочная дисперсия, среднее квадратическое отклонение, мода, медиана.
Характеристики статистического распределения выборки применяется для оценки неизвестных параметров теоретического распределения вероятностей.
Пусть изучается генеральная совокупность объемом N относительно количественного признака Х.
Для изучения качественного признака генеральной совокупности извлечена выборка значений признака Х1,Х2,Х3,…Хn.
Средняя величина, вычисленная на основании ряда чисел, каждое из которых встречается один раз, называется простой средней арифметической .
(1.1)
Для того, чтобы охарактеризовать рассеяние значений изучаемого признака выборки около выборочной средней Х, вводят понятие выборочной дисперсии.
( 1.2)
4)Среднее квадратичное отклонение (стандартное отклонение) равно корню квадратному из дисперсии:
Доверительным интерваломназывается интервал значений случайной величины, в котором с заданной вероятностью заключена средняя арифметическая генеральной совокупности.
Медианой (Ме) называется такое среднее значение, которое делит совокупность значений величины Хi на две равные по количеству членов части, причем в одной из них все значения Хi меньше медианы, а в другой – больше.
Для ранжированного вариационного ряда при нечетном числе членов,
т.е. при n= 2m+1 медианой будет значение среднего ряда, т.е. Ме=хm+1,
Например, для ряда: 3,6,7,9, 11,12,13,15,17. Ме=11
Для ряда: 6,12,7,8,11,10,7,9,12,9,13,14,15 Ме=10, т.к. если все данные ранжировать, то получится ряд:
6,7,7,8,9,9,10,11,12,12,13,14,15
Если же число членов ряда четное, т.е. n=2m, то за медиану принимается среднее арифметическое двух значений хm и хm+1, находящихся в середине ряда, т.е. .
Например, для ряда 2,4,5,7,11,14,15,18 Ме=(7+11)/2=18/2=9
Для ряда: 6,7,7,8,9,10,11,12,12,13,14 Ме=(9+10)/2=4,5
Модой (Мо) называется наиболее вероятное значение случайной величины или то его значение этой величины, частота которого наибольшая.
Пример 4.Распределение лейкоцитов по числу поглощенных ими бактерий приведено в таблице.
| Число поглощенных бактерий | |||||||||||
| Количество лейкоцитов |
Наибольшая частота 241 отвечает признаку, равному 2, следовательно Mо=2
©2015 arhivinfo.ru Все права принадлежат авторам размещенных материалов.
arhivinfo.ru
Ряды распределения -
Упорядоченное расположение единиц совокупности по изучаемому признаку представляет собой ряд распределения.
Любой ряд распределения позволяет получить информацию:
– о возможных вариантах значения признака, которые встречаются в данной статистической совокупности
– как часто встречаются отдельные значения данного признака.
В зависимости от признака различают:
-вариационные ряды распределения
-атрибутивные ряды распределения.
Элементы ряда распределения:
-
Значение признака (варианта) -хi
-
Частота fi – число единиц совокупности с данным значением признака.
Сумма всех частот определяет численность всей совокупности.
-
Частостью называются частоты, выраженные в долях единицы или в %.
-
Накопленная частота – частота нарастающим итогом.
-
Накопленная частость – частость нарастающим итогом.
Если варианты расположены по возрастанию или убыванию, то ряды называются ранжированными.
В зависимости от характера вариации признака различают:
– дискретные вариационные ряды распределения
– интервальные ряды распределения.
Ряды распределения удобнее всего анализировать при помощи их графического изображения. Наглядное представление о характере изменения частот вариационного ряда дают полигон и гистограмма.
Полигон используется при изображении дискретных вариационных рядов. По оси абсцисс в одинаковом масштабе откладываются ранжированные значения варьирующего признака, а по оси ординат – величины частот. Точки, полученные на пересечении абсцисс и ординат, соединяются прямыми линиями, в результате получают ломаную линию, называемую полигоном частот.
Рис.3. Полигон распределения студентов по полученной оценке.
Для изображения интервального вариационного ряда применяется гистограмма. По оси абсцисс – длина интервала, по оси ординат – частоты. Гистограмма может быть преобразована в полигон распределения, если соединить прямыми линиями середины сторон прямоугольников.
Рис. 4. Гистограмма распределения студентов по заработанным баллам
При построении гистограммы распределения ряда с неравными интервалами по оси ординат наносят плотность распределения признака в соответствующих интервалах.
Для графического изображения вариационных рядов может использоваться кумулята – ряд накопленных частот. При построении кумуляты интервального ряда распределения по оси абсцисс откладываются варианты ряда, по оси ординат – накопленные частоты, которые наносят на поле графиков перпендикуляров к оси абсцисс в верхних границах интервалов. Затем перпендикуляры соединяют ломаной.
einsteins.ru