Параллельные методы умножения матрицы на вектор (стр. 1 из 2). На вектор умножение матриц
Умножение матрицы на вектор, формула и примеры
Умножение матрицы на вектор производится по правилу «строка на столбец». При умножении матрицы на вектор-столбец число столбцов в матрице должно совпадать с числом строк в векторе-столбце. Результатом умножения матрицы на вектор-столбец есть вектор-столбец:
При умножении матрицы на вектор-строку, умножаемая матрица может быть только вектором-столбцом, причем количество строк в векторе-столбце должно совпадать с количеством столбцов в векторе-строке. Результатом такого умножения будет квадратная матрица соответствующей размерности:
Примеры умножения матриц на вектора
| Понравился сайт? Расскажи друзьям! | |||
ru.solverbook.com
Умножение комплексного вектора на матрицу
| Результат умножения вектора-строки на матрицу с*A |
| Результат умножения матрицы на вектор-столбец A*b |
Умножение Вектора на матрицу
Каждый вектор можно рассматривать как одностолбцовую или однострочную матрицу. Одностолбцовую матрицу будем называть вектор-столбцом, а однострочную матрицу - вектор-строкой.
Если A-матрица размера m*n, то вектор столбец b имеет размер n, а вектор строка b имеет размер m.
Таким образом, что бы умножить матрицу на вектор, надо рассматривать вектор как вектор-столбец. При умножении вектора на матрицу, его нужно рассматривать как вектор -строку.
Пример.
Умножить матрицу
на комплексный вектор
Получаем результат
| Результат умножения матрицы на вектор A*b |
| Результат умножения вектора на матрицу b*A |
Как видите при неизменной размерности вектора, у нас могут существовать два решения.
Хотелось бы обратить Ваше внимание на то что матрица в первом и втором варианте, несмотря на одинаковые значения, совершенно разные (имеют различную размерность)
В первом случае вектор считается как столбец и тогда необходимо умножать матрицу на вектор, а во втором случае у нас вектор-строка и тогда у нас произведение вектора на матрицу.
Свойства умножения матрицы на вектор
- матрица - вектор столбец - вектор-строка - произвольное число1. Произведение матрицы на сумму векторов-столбцов равна сумме произведений матрицы на каждый из векторов
2. Произведение суммы векторов-строк на матрицу равна сумме произведений векторов на матрицу
3. Общий множитель вектора можно вынести за пределы произведения матрицы на вектор/вектора на матрицу
4.Произведение вектора-строки на произведение матрицы и вектора столбца, равноценно произведению произведения вектора-строки на матрицу и вектора-столбца.
Удачных расчетов!!
- Умножение матриц с комплексными значениями онлайн >>
www.abakbot.ru
умножение матрицы на вектор | C++ для приматов
Даны квадратная матрица [latex]A[/latex] порядка [latex]n[/latex], векторы [latex]x[/latex] и [latex]y[/latex] с [latex]n[/latex] элементами. Получить вектор [latex]A(x+y)[/latex].
Примеры:
| Размерность матрицы | Матрица | Вектор x | Вектор y | Результирующий вектор A(x+y) |
| 2 | 2 3 3 2 | 3 4 | 5 6 | 46 44 |
| 3 | 2 1 4 5 2 6 3 4 8 | 2 2 2 | 4 4 4 | 42 78 90 |
| 4 | 1 2 3 4 3 4 1 6 2 3 8 1 4 5 0 8 | 1 2 3 4 | 5 4 3 2 | 60 84 84 102 |
| 5 | 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 | 4 6 7 8 0 | 2 8 9 3 1 | 0 0 16 0 0 |
Алгоритм решения: Вводим матрицу [latex]A[/latex] порядка [latex]n[/latex]. Вводим векторы [latex]x[/latex] и [latex]y[/latex], прибавляем векторы [latex]x[/latex] и [latex]y[/latex]. После умножаем матрицу [latex]A[/latex] на вектор [latex]x + y[/latex] и получаем вектор [latex]A(x + y)[/latex]. С помощью цикла выводим результирующий вектор.
Код программы :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
#include <iostream> using namespace std; int main() { int n; cin >> n; int x[n]; int y[n]; int z[n]; int A[n][n]; int result_vector[n]; for (int i = 0; i < n; i++){ for (int j = 0; j < n; j++) cin >> A[i][j]; } for (int i = 0; i < n; i++){ cin>>x[i]; } for (int i = 0; i < n; i++){ } for (int i = 0; i < n; i++){ z[i]=x[i]+y[i]; } for(int i=0; i<n; i++) { result_vector[i]=0; for(int j=0; j<n; j++) { result_vector[i]+=A[i][j]*z[j]; } } for(int i=0; i<n; i++) { cout << result_vector[i] << endl; } return 0; } |
Оригинал кода можно увидеть перейдя по ссылке
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
import java.util.*; import java.lang.*; import java.io.*; /* Name of the class has to be "Main" only if the class is public. */ class Ideone { public static void main (String[] args) throws java.lang.Exception { int n; Scanner in = new Scanner(System.in); n = in.nextInt(); double []x = new double[n]; double []y = new double[n]; double []z = new double[n]; double [] result_vector = new double[n]; double [][] A = new double[n][n]; for (int i = 0; i < n; i++){ for (int j = 0; j < n; j++){ A[i][j]=in.nextDouble(); } } for (int i = 0; i < n; i++){ x[i]=in.nextDouble(); } for (int i = 0; i < n; i++){ y[i]=in.nextDouble(); } for (int i = 0; i < n; i++){ z[i]=x[i]+y[i]; } for(int i=0; i<n; i++) { result_vector[i]=0; for(int j=0; j<n; j++) { result_vector[i]+=A[i][j]*z[j]; } } for(int i=0; i<n; i++) { System.out.printf("%.6f ",result_vector[i]); } } } |
Оригинал кода можно увидеть перейдя по ссылка
Posted in 6. Многомерные массивы. Tagged умножение матрицы на вектор.Задача. Дана квадратная матрица порядка n. Получить вектор Ab, где b-вектор, элементы которого вычисляются по формулам:
i=(1,…,n).
Тесты:
| Вход | Выход | Комментарий |
| 41 2 1 11 3 6 91 2 1 11 6 3 18 | 1.72222 4 1.72222 4 | Пройден |
| 30 0 01 1 12 2 2 | 0 1.5 3 | Пройден |
| 41 2 2 93 4 1 181 1 1 10 0 0 0 | 2.5 5 1.55556 0 | Пройден |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
#include <iostream> using namespace std;
int main() { int n; cin>>n; double b[n]; for (int i=0; i<n; i++) { if((i+1)%2==0) b[i]=1.0/((i+1)*(i+1) + 2); else b[i]=1.0/(i+1); }
double A[n][n]; for (int i=0; i<n; i++) for (int j=0; j<n; j++) cin>>A[i][j]; double Ab[n]; for (int i=0; i<n; i++) { Ab[i]=0; for (int j=0; j<n; j++) { Ab[i]+=A[i][j]*b[j]; } } for (int i=0; i<n; i++) cout<<Ab[i]<<" "; return 0; } |
Согласно условию находим вектор b. По формуле [latex]Ab_{i}=\sum_{j=1}^{n}A_{ij}b_{j}[/latex], i=(0,…,n) находим произведение матрицы на вектор.
С работой программы можно ознакомится здесь.
Posted in 6. Многомерные массивы. Tagged квадратная матрица, умножение матрицы на вектор.cpp.mazurok.com
Умножение матрицы на вектор при разделении данных по строкам
Данный алгоритм основан на представлении матрицы непрерывными наборами (горизонтальными полосами) строк. Полученные полосы распределяются по процессорам вычислительной системы. Вектор b копируется на все процессоры. Перемножение полосы матрицы на вектор (а данная операция может быть выполнена процессорами параллельно) приводит к получению блока элементов результирующего вектора с. Для объединения результатов расчета и получения полного вектора c на каждом из процессоров вычислительной системы необходимо выполнить операцию обобщенного сбора данных.
4.2.2. Умножение матрицы на вектор при разделении данных по столбцам
Другой подход к параллельному умножению матрицы на вектор основан на разделении исходной матрицы на непрерывные наборы (вертикальные полосы) столбцов. Вектор b при таком подходе разделен на блоки. Вертикальные полосы исходной матрицы и блоки вектора распределены между процессорами вычислительной системы.
Параллельный алгоритм умножения матрицы на вектор начинается с того, что каждый процессор i выполняет умножение своей вертикальной полосы матрицы А на блок элементов вектора b, в итоге на каждом процессоре получается вектор промежуточных результатов c'(i). Далее для получения элементов результирующего вектора с процессоры должны обменяться своими промежуточными данными между собой.
4.2.3. Умножение матрицы на вектор при блочном разделении данных
Рассмотрим теперь параллельный алгоритм умножения матрицы на вектор, который основан на ином способе разделения данных – на разбиении матрицы на прямоугольные фрагменты (блоки). При таком способе разделения данных исходная матрица A представляется в виде набора прямоугольных блоков. Вектор b также должен быть разделен на блоки. Блоки матрицы и блоки вектора распределены между процессорами вычислительной системы. Логическая (виртуальная) топология вычислительной системы в данном случае имеет вид прямоугольной двумерной решетки. Размеры процессорной решетки соответствуют количеству прямоугольных блоков, на которые разбита матрица A. На процессоре pi,j, находящемся на пересечении i-й строки и j-го столбца процессорной решетки, располагается блок Ai,j матрицы A и блок bj вектора b.
После перемножения блоков матрицы A и вектора b каждый процессор pi,j будет содержать вектор частичных результатов c'(i,j). Поэлементное суммирование векторов частичных результатов для каждой горизонтальной строки процессорной решетки позволяет получить результирующий вектор c.
4.3. Матричное умножение
Задача умножения матрицы на матрицу определяется соотношениями:
(для простоты изложения материала будем предполагать, что перемножаемые матрицы A и B являются квадратными и имеют порядок n×n). Как следует из приведенных соотношений, вычислительная сложность задачи является достаточно высокой (оценка количества выполняемых операций имеет порядок n3).
Основу возможности параллельных вычислений для матричного умножения составляет независимость расчетов для получения элементов сij результирующей матрицы C. Тем самым, все элементы матрицы C могут быть вычислены параллельно при наличии n2 процессоров, при этом на каждом процессоре будет располагаться по одной строке матрицы A и одному столбцу матрицы B. При меньшем количестве процессоров подобный подход приводит к ленточной схеме разбиения данных, когда на процессорах располагаются по несколько строк и столбцов (полос) исходных матриц.
Другой широко используемый подход для построения параллельных способов выполнения матричного умножения состоит в применении блочного представления матриц, при котором исходные матрицы A, B и результирующая матрица C рассматриваются в виде наборов блоков (как правило, квадратного вида некоторого размера m×m). Тогда операцию матричного умножения матриц A и B в блочном виде можно представить следующим образом:
где каждый блок Cij матрицы C определяется в соответствии с выражением:
Полученные блоки Cij также являются независимыми, и, как результат, возможный подход для параллельного выполнения вычислений может состоять в расчетах, связанных с получением отдельных блоков Cij, на разных процессорах. Применение подобного подхода позволяет получить многие эффективные параллельные методы умножения блочно-представленных матриц.
studfiles.net
Параллельные методы умножения матрицы на вектор
ФЕДЕРАЛЬНОЕ АГЕНСТВО ПО ОБРАЗОВАНИЮ
ГОУВПО “ПЕРМСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ”
Кафедра прикладной математики и информатики
Параллельные методы умножения матрицы на вектор
( лаба №1 )
Пермь 2010
Цель лабораторной работы.
Реализация последовательного и параллельных алгоритмов умножения матрицы на вектор при использовании 2-х ядерной вычислительной системы с общей памятью.
Постановка задачи.
В результате умножения матрицы
и вектора , получается вектор , каждый i -ый элемент которого есть результат скалярного умножения i -й строки матрицы (обозначим эту строчку ) и вектора .Тем самым получение результирующего вектора
предполагает повторение однотипных операций по умножению строк матрицы и вектора . Каждая такая операция включает умножение элементов строки матрицы и вектора ( операций) и последующее суммирование полученных произведений (операций).Общее количество необходимых скалярных операций есть величина
.- Поcледовательный алгоритм умножения матрицы на вектор
void SerialResultCalculation(double* pMatrix, double* pVector,
double* pResult, int Size) {
int i, j; // Loop variables
for (i=0; i<Size; i++) {
pResult[i]=0;
for (j=0; j<Size; j++)
pResult[i] += pMatrix[i*Size+j]*pVector[j];
}
}
- Умножение матрицы на вектор при разделении данных по строкам.
Базовая подзадача - скалярное умножение одной строки матрицы на вектор. После завершения вычислений каждая базовая подзадача определяет один из элементов вектора результата c .
В общем виде схема информационного взаимодействия подзадач в ходе выполняемых вычислений показана на рис.1. Количество вычислительных операций для получения скалярного произведения одинаково для всех базовых подзадач.
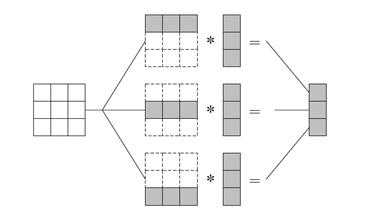
Рисунок 1 . Организация вычислений при выполнении параллельного алгоритма умножения матрицы на вектор, основанного на разделении матрицы по строкам.
Каждый поток параллельной программы использует только «свои» данные, ему не требуются данные, которые в данный момент обрабатывает другой поток, нет обмена данными между потоками, не возникает необходимости синхронизации. Т.е. практически нет накладных расходов на организацию параллелизма (за исключением расходов на организацию и закрытие параллельной секции), и можно ожидать линейного ускорения. Однако, как будет видно из представленных результатов, ускорение далеко от линейного.
Время решения задачи одним потоком складывается из времени, когда процессор непосредственно выполняет вычисления, и времени, которое тратится на чтение необходимых для вычислений данных из ОП в кэш. При этом время, необходимое на чтение данных, может в несколько раз превосходить время счета.
Процесс выполнения последовательного алгоритма умножения матрицы на вектор может быть представлен диаграммой, изображенной на рис.2.
Рисунок 2. Диаграмма состояний процесса выполнения последовательного алгоритма
умножения матрицы на вектор.
Время выполнения последовательного алгоритма складывается из времени вычислений и времени доступа к памяти:
, где - это количество выполненных операций, - время выполнения одной операции, - размерность матрицы. , где - объем данных, которые необходимо закачать в кэш процессора, - скорость доступа (пропускная способность канала доступа) ОП.Таким образом,
.Для оценки
, измерим время выполнения последовательного алгоритма при, т.к. матрица и вектор полностью поместятся в кэш ВЭ. (У нас размер кэш равен 2048 кбайт, поэтому ). Чтобы исключить необходимость выборки данных из ОП, перед началом вычислений заполним матрицу и вектор случайными числами – выполнение этого действия гарантирует закачку данных в кэш. Далее при решении задачи все время будет тратиться на вычисления, так как нет необходимости загружать данные из ОП.Получим
0,00000308.Тогда
Теперь, оценим
при : 8 121 537 238,29В таблице 1 и на рис.3 представлено сравнение реального времени последовательного алгоритма умножения матрицы на вектор и теоретического.
Таблица 1. Сравнение экспериментального и теоретического времени выполнения последовательного
алгоритма умножения матрицы на вектор.


Рисунок 3. График зависимости экспериментального и теоретического времени выполнения последовательного алгоритма от объема исходных данных (ленточное разбиение матрицы по строкам
В многоядерных процессорах Intel архитектуры Core 2 Duo ядра процессоров разделяют общий канал доступа к памяти. Т.е., несмотря на то, что вычисления могут выполняться ядрами параллельно , доступ к памяти осуществляется строго последовательно. Следовательно, время
выполнения параллельного алгоритма в системе с вычислительными элементами, с использованием потоков и при описанной выше схеме доступа к памяти может быть оценено при помощи следующего соотношения: .void ParallelResultCalculation_rows (double* pMatrix, double* pVector,
double* pResult, int Size) {
int i, j; // Loop variables
#pragma omp parallel private (i,j)
#pragma omp for
for (i=0; i<Size; i++) {
for (j=0; j<Size; j++)
pResult[i] += pMatrix[i*Size+j]*pVector[j];
}
}
Результаты вычислительных экспериментов приведены в таблице 2. Времена выполнения алгоритмов указаны в секундах.
Ускорение есть результат деления времени работы последовательного алгоритма на время работы параллельного.
Таблица 2. Результаты вычислительных экспериментов для параллельного алгоритма умножения
матрицы на вектор при ленточной схеме разделении данных по строкам.


Рисунок 4. Зависимость ускорения от количества исходных данных при выполнении параллельного алгоритма умножения матрицы на вектор, основанного на ленточном горизонтальном разбиении матрицы

Рисунок 5. График зависимости экспериментального и теоретического времени выполнения параллельного алгоритма от объема исходных данных при использовании двух потоков (ленточное разбиение матрицы по строкам)
mirznanii.com
Умножение комплексного вектора на матрицу
| Результат умножения вектора-строки на матрицу с*A |
| Результат умножения матрицы на вектор-столбец A*b |
Умножение Вектора на матрицу
Каждый вектор можно рассматривать как одностолбцовую или однострочную матрицу. Одностолбцовую матрицу будем называть вектор-столбцом, а однострочную матрицу - вектор-строкой.
Если A-матрица размера m*n, то вектор столбец b имеет размер n, а вектор строка b имеет размер m.
Таким образом, что бы умножить матрицу на вектор, надо рассматривать вектор как вектор-столбец. При умножении вектора на матрицу, его нужно рассматривать как вектор -строку.
Пример.
Умножить матрицу
на комплексный вектор
Получаем результат
| Результат умножения матрицы на вектор A*b |
| Результат умножения вектора на матрицу b*A |
Как видите при неизменной размерности вектора, у нас могут существовать два решения.
Хотелось бы обратить Ваше внимание на то что матрица в первом и втором варианте, несмотря на одинаковые значения, совершенно разные (имеют различную размерность)
В первом случае вектор считается как столбец и тогда необходимо умножать матрицу на вектор, а во втором случае у нас вектор-строка и тогда у нас произведение вектора на матрицу.
Свойства умножения матрицы на вектор
- матрица - вектор столбец - вектор-строка - произвольное число1. Произведение матрицы на сумму векторов-столбцов равна сумме произведений матрицы на каждый из векторов
2. Произведение суммы векторов-строк на матрицу равна сумме произведений векторов на матрицу
3. Общий множитель вектора можно вынести за пределы произведения матрицы на вектор/вектора на матрицу
4.Произведение вектора-строки на произведение матрицы и вектора столбца, равноценно произведению произведения вектора-строки на матрицу и вектора-столбца.
Удачных расчетов!!
- Умножение матриц с комплексными значениями онлайн >>
www.abakbot.ru
Алгоритм умножения матрицы на вектор
Алгоритм умножения матрицы (для простоты возьмем квадратную матрицу) размерности на вектор размерности можно представить как скалярных умножений векторов, получающихся из строк матрицы на вектор . Если строки матрицы слоистым образом распределены по процессорам и вектор хранится на каждом процессоре, то параллельный алгоритм можно записать следующим образом:
Шаг 1: на
Шаг 2: на
Шаг 3:
На втором шаге на каждом процессоре параллельно вычисляются соответствующие блоки результирующего вектора , затем (если это необходимо) на третьем шаге они пересылаются на первый процессор.
Предположим, что столбцы матрицы распределены слоистым образом по процессорам. В этом случае необходимо модифицировать алгоритм с учетом хранения матрицы. Результат матрично-векторного произведения можно получить, умножив каждый столбец матрицы на соответствующий элемент вектора и сложив получившиеся вектора. Степень параллелизма этого алгоритма меньше, чем в предыдущем, и обусловлена тем, что приходится осуществлять суммирование.
Условно, по шагам алгоритм записывается следующим образом:
Шаг 1: на
Шаг 2: на
Шаг 3: на
Шаг 4:
Шаг 5: на
На втором шаге осуществляется покомпонентное умножение векторов, на третьем – частичное суммирование, на четвертом – пересылка частичных сумм на первый процессор, на последнем – завершающее суммирование.
Матрично-векторное умножение обычно является частью более широкого процесса вычислений и для выбора того или иного алгоритма главную роль играет способ хранения и в момент, когда требуется их произведение. Например, если и уже находятся в памяти -го процессора, то эффективнее использовать второй алгоритм, хотя степень параллелизма в нем ниже, чем в первом. Еще один важный фактор при выборе параллельного алгоритма - желаемое расположение результата по окончании операции умножения: во втором алгоритме вектор-результат размещается в памяти одного процессора, тогда как в первом он распределен по процессорам.
program EXAMPLE
include 'mpif.h'
integer my_id, np, comm, tag, count, ierr, n,q
integer i,j,k
integer a(100,100),b(100)
integer c(100,100),a1(100,100),a2(100,100)
integer status(MPI_STATUS_SIZE)
double precision t1,tfinish
call MPI_Init(ierr)
comm=MPI_COMM_WORLD
call MPI_Comm_rank(COMM, my_id, ierr)
call MPI_Comm_size(COMM, np, ierr)
print *, 'Process ', my_id, ' of ', np, ' is alive'
! Инициализация матриц
t1=MPI_Wtime()
call MPI_Bcast(n,1,MPI_INTEGER,0,COMM,ierr)
call MPI_Bcast(b,n,MPI_INTEGER,0,COMM,ierr)
call MPI_Scatter(a,int(n*n/np),MPI_INTEGER,a1,
* int(n*n/np),MPI_INTEGER,0,COMM,ierr)
c=0
do j=1,n,1
do i=1,int(n/np),1
do k=1,n,1
c(i+int(n/np)*my_id,j)=
*c(i+int(n/np)*my_id,j)+a1(k,i)*b(k)
end do
end do
end do
call MPI_Reduce(c,a2,n*n,MPI_INTEGER,MPI_SUM,
*0, COMM,ierr)
t1=MPI_Wtime()-t1
write(*,*) 'Dim = ',n,' the time is ',t1
call MPI_Finalize(ierr)
stop
end
Задание: Алгоритм умножения матриц
Реализовать любой вариант параллельного умножения матриц.
Пример:
Приведенные параллельные алгоритмы матрично-векторного произведения естественным образом обобщаются на задачу умножения матриц. Приведенные же ниже алгоритмы будут обсуждаться с точки зрения того, как хранились матрицы до операции произведения и после нее.
Для простоты возьмем квадратные матрицы и размерности .
Первый вариант параллельного алгоритма матричного умножения будем строить, предполагая, что матрица распределена по процессорам слоистым образом по строкам, а матрица - целиком. В этом случае искомый результат можно получить, выполнив параллельно на каждом процессоре скалярных произведений.
Приведем алгоритм:
Шаг 1: на
Шаг 2: на (причем циклы по индексам расположены в следующей последовательности
Шаг 3:
Второй вариант параллельного алгоритма матричного умножения будем строить, предполагая, что матрица распределена по процессорам слоистым образом по столбцам, а матрица - целиком. В этом случае искомый результат можно получить, выполнив параллельно на каждом процессоре умножение соответствующих столбцов матрицы на соответствующие элементы строк матрицы , затем необходимо осуществить частичное суммирование получившихся произведений и на последнем шаге, переслав матрицы с частичными суммами на один процессор, закончить суммирование. Алгоритм опустим ввиду его громоздкости и очевидности.
Возможные способы хранения исходных матриц порождают другие алгоритмы. Например, матрица распределена по процессорам слоистым образом по строкам, а матрица - целиком, или распределена по процессорам слоистым образом по столбцам, а - целиком. Алгоритмы при этом схожи с рассмотренными выше.
Возможно также построение алгоритмов, которые основаны на блочном распределении матриц и по процессорам.
Если разбиения обеих матриц на блоки согласованы, то
,
где или - миноры соответствующих матриц. Это представление можно реализовать разными алгоритмами. Пусть, например, число процессоров равно (числу миноров матрицы . При условии, что матрицы и распределены соответствующим образом по процессорам, все миноры матрицы можно вычислять одновременно.
studfiles.net