Как определить кодировку файла? Определить кодировку файла онлайн
Universal online Cyrillic decoder - recover your texts
Version: 20180502
Output
The resulting text will be displayed here...
| Guestbook Please link to this site! <a href="http://2cyr.com/decode/">Universal Cyrillic decoder</a> | Donate via PayPalYou can help keeping the service running and without ads. Donate Bitcoins192KAYCwZsHNTug634rPkGChiVzXufXsGw | Custom WorkFor a small fee I can help you quickly recode/recover large pieces of data - texts, databases, websites... or write custom functions you can use (invoice available).Contact me! mailto:5ko [snail] 5ko [period] fr?subject=Request%20via%202cyr [period] com |
About the program
Welcome! You may find this site useful, if you have recieved some texts that you believe are written in the Cyrillic alphabet, but instead are displayed in some strange combination of bizarre characters. This program will try to guess the encoding, and if it does not, it will show samples, examples of all encoding-combinations, so as you will be able to select the good one.
How to
- Paste the text to decypher in the big text area. The first few words will be analysed so they should be (scrambled) in supposed Cyrillic.
- The program will try to decypher the text and will print the result below.
- If the translation is successful, you will see the text in Cyrillic characters and will be able to copy it and save it if it's important.
- If the translation isn't successful (still the text is not in Cyrillic but in the same or other unintelligible characters), you can choose from the newly created select-listbox the variant that is in Cyrillic (if there are more than one, select the longest). By pressing the button OK you will have the correct text converted.
- If the text is not totally converted, try all other variants in Cyrillic from the select-listbox.
Limits
- If your text contains question marks "???? ?? ??????", the problem is with the sender and no recovery will be possible. Ask them to resend the text, eventually as an ordinary text file or in LibreOffice/OpenOffice/MSOffice format.
- There is no claim that every text is decypherable, even if you are certain that the text is in Cyrillic.
- The analyzed and converted text is limited to 100 KiB.
- A 100% precision is not always achieved - in a conversion from a codepage to another code page, some characters may be lost, like the Bulgarian quotes or rarely some single letters. Some of this depends on your Windows Clipboard character handling.
- The program will try a maximum of 6321 variants in two or three levels: if there had been a multiple encoding like koi8(utf(cp1251(utf))), it will not be detected or tested. Usually the possible and displayed correct variants are between 32 and 255.
- If a part of the text is encoded with one code page, and another part - with another code page, the program could recognize only one of the parts at a time.
Terms of use
Please notice that this freeware program is created with the hope that it would be useful, but has no warranty, not even an implied warranty for fitness for any particular use. Please use it at your own risk.
If you have very long texts to translate, please make sure you have a backup copy.
What's new
- October 2017 : Added "Select all / Copy" button.
- July 2016 : SSL Certificate installed, you can now access the Decoder on a secure connection.
- October 2013 : I am trying different optimizations for the system which should make the decoder run faster and handle more text. If you notice any problem, please notify me ASAP.
- March 2013 : My hosting provider sent me a warning that the Decoder is using too much server CPU power and its processes were killed more than 100 times. I am making some changes so that the program will use less CPU, especially when reposting a previously sampled text, however, the decoded form may load somewhat slower. Please contact me if you have some difficulties using the program.
- 2012-08-09 : Added French translation, thanks to Arnaud D.
- 2011-03-06 : Added Belorussian translation, thanks to Зыль and Aliaksandr Hliakau.
- 31.07.10 : Added Serbian translation, thanks to Miodrag Danilovic (Boston - Beograd).
- 07.05.09 : Raised limit of MAX text size to 50 kiB.
- may 2009 : Added Ukrainian interface thanks to Barmalini.
- 2008-2009 : A number of small fixes and tweaks of the detection algorythm. Changed interface to default to automatic decoding.
- 12.08.07 : Fixed Russian language translation, thanks to Petr Vasilyev. This page will be significantly restructured in the near future.
- 10.11.06 : Three new postfilters added: "base64", "unix-to-unix" и "bin-to-hex", theoretically the tested combinations are 4725. Changes to the frequency analysis function (testing).
- 11.10.06 : The main site is on a new hardware server, should run faster.
- 11.09.06 : The program now uses PHP5 and should run times faster.
- 19.08.06 : Because of a broken DNS entry, this site was inaccessible from 06:00 on 15 august up to 15:00 on 18 august. That was the reason for me to set two "mirror" sites (5ko.free.fr/decode and www.accent.bg/decode) with the same program. If the original has a problem, you can find the copies in Google and recover your texts.
- 17.06.06 : Added two more antique cyrillic encodings, MIK и KOI-7, but you better not need them.
- 03.03.06 : Added Slovak translation, thanks to Martin from KPR Slovakia.
- 15.02.06 : More encodings added and tested.
- 20.10.05 : Small improvement to the frequency-analysis function: for texts, written in all-capital letters.
- 14.10.05 : Two more gmail-cyrillic encodings were added. Theoretically the tested combinations are 2112.
- 15.06.05 : Russian language interface was added. Big thanks to chAlx!
- 16.02.05 : One more postfilter decoding is added, for strings like this: "%u043A%u0438%u0440%u0438%u043B%u0438%u0446%u0430".
- 05.02.05 : More encodings tests added, the number of tested encodings is doubled, but thus the program may work slightly slower.
- 03.02.05 : The frequency analysis function that detects the original encoding works much better now. Currently the program recognises most of the encodings if the first few words are not too weird. It although still needs some improvement.
- 15.01.05 : The input text limit is raised from 10 to 20 kB.
- 01.12.04 : First public release.
Back to the Latin to Cyrillic convertor.
Как определить кодировку файла?
Существует много способов кодирования информации, в процессе которого сообщение преобразуется в комбинацию символов. Часто бывает, что при посещении веб-страницы на ней вместо букв возникают непонятные символы.
Вам понадобится
- - компьютер с доступом в интернет.
Инструкция
Вам понадобится
- Текстовый редактор, работающий с большим числом кодировок, или программа-декодер.
Инструкция
- Один из самых известных декодеров текста
Шифрование online
Здесь собраны наиболее часто используемые методы шифрования и преобразования, которых постоянно не оказывается под рукой, когда в них возникает срочная надобность. Например, вычислить md5 хеш или раскодировать url. А найти в интернете хорошую реализацию часто очень непросто.Прошу обратить внимание, что сайт использует кодировку UTF-8. Поэтому результаты шифрования одним и тем же алгоритмом одних данных в разных кодировках могут не совпадать. Это относится к символам, не принадлежащим английскому алфавиту.
Без ключа





Утилиты




Симметричные


Асимметричные

Математические


crypt-online.ru
Text To Hex / Hex To Text
Описание: Text в Hex / Hex в Text - преобразование текста в шестнадцатеричные коды его символов и обратно. Работает для текста в кодировках Windows-1251, UTF-16. Декодирует UTF-8 текст с кириллицей, который при закодировании в JSON переводится штатной php функцей json_encode() в \uXXXX кодировку.В математике и вычислениях шестнадцатеричная (также базовая 16, или шестнадцатеричная) - это позиционная система счисления с основанием 16. Он использует шестнадцать различных символов, чаще всего символы 0-9 для представления значений от нуля до девяти, и A, B, C, D, E, F (или альтернативно a, b, c, d, e, f) для представления значений от десяти до пятнадцати.
Шестнадцатеричные цифры широко используются разработчиками компьютерных систем и программистами. Поскольку каждая шестнадцатеричная цифра представляет собой четыре двоичные цифры (биты), она позволяет более удобное для человека представление двоичных кодированных значений. Одна шестнадцатеричная цифра представляет собой кусочек (4 бита), который составляет половину октета или байта (8 бит). Например, один байт может иметь значения в диапазоне от 00000000 до 11111111 в двоичном виде, но это может быть более удобно представлено как 00 до FF в шестнадцатеричном виде.
В контексте, не относящемся к программированию, индекс обычно используется, чтобы дать rix, например, десятичное значение 10,995 было бы выражено в шестнадцатеричном виде как 2AF316. Несколько обозначений используются для поддержки шестнадцатеричного представления констант в языках программирования, обычно включающих префикс или суффикс. Префикс "0x" используется в языках C и связанных языках, где это значение может быть обозначено как 0x2AF3.
Ресурсы:
crypt-online.ru
Перевод кодировки онлайн

Если вам прислали текстовый документ, информация в котором отображается в виде странных и непонятных символов, можно предположить, что автор использовал кодировку, не распознаваемую вашим компьютером. Для изменения кодировки существуют специальные программы-декодеры, однако куда проще воспользоваться одним из онлайн-сервисов.
Сайты для перекодировки онлайн
Сегодня мы расскажем о самых популярных и действенных сайтах, которые помогут угадать кодировку и изменить ее на более понятную для вашего ПК. Чаще всего на таких сайтах работает автоматический алгоритм распознавания, однако в случае необходимости пользователь всегда может выбрать подходящую кодировку в ручном режиме.
Способ 1: Универсальный декодер
Декодер предлагает пользователям просто скопировать непонятный отрывок текста на сайт и в автоматическом режиме переводит кодировку на более понятную. К преимуществам можно отнести простоту ресурса, а также наличие дополнительных ручных настроек, которые предлагают самостоятельно выбрать нужный формат.
Работать можно только с текстом, размер которого не превышает 100 килобайт, кроме того, создатели ресурса не гарантируют, что перекодировка будет в 100% случаев успешной. Если ресурс не помог – просто попробуйте распознать текст с помощью других способов.
Перейти на сайт Универсальный декодер
- Копируем текст, который нужно декодировать, в верхнее поле. Желательно, чтобы в первых словах уже содержались непонятные символы, особенно в случаях, когда выбрано автоматическое распознавание.

- Указываем дополнительные параметры. Если необходимо, чтобы кодировка была распознана и преобразована без вмешательства пользователя, в поле «Выберите кодировку» щелкаем на «Автоматически». В расширенном режиме можно выбрать начальную кодировку и формат, в который нужно преобразовать текст. После завершения настройки щелкаем на кнопку «ОК».

- Преобразованный текст отобразится в поле «Результат», оттуда его можно скопировать и вставить в документ для последующего редактирования.
Обратите внимание на то, что если в отправленном вам документе вместо символов отображается «???? ?? ??????», преобразовать его вряд ли получится. Символы появляются из-за ошибок со стороны отправителя, поэтому просто попросите отправить вам текст повторно.
Способ 2: Студия Артемия Лебедева
Еще один сайт для работы с кодировкой, в отличие от предыдущего ресурса имеет более приятный дизайн. Предлагает пользователям два режима работы, простой и расширенный, в первом случае после декодировки пользователь видит результат, во втором случае видна начальная и конечная кодировка.
Перейти на сайт Студия Артемия Лебедева
- Выбираем режим декодировки на верхней панели. Мы будем работать с режимом «Сложно», чтобы сделать процесс более наглядным.
- Вставляем нужный для расшифровки текст в левое поле. Выбираем предполагаемую кодировку, желательно оставить автоматические настройки — так вероятность успешной дешифровки возрастет.

- Щелкаем на кнопку «Расшифровать».

- Результат появится в правом поле. Пользователь может самостоятельно выбрать конечную кодировку из ниспадающего списка.
С сайтом любая непонятная каша из символов быстро превращается в понятный русский текст. На данный момент работает ресурс со всеми известными кодировками.
Способ 3: Fox Tools
Fox Tools предназначен для универсальной декодировки непонятных символов в обычный русский текст. Пользователь может самостоятельно выбрать начальную и конечную кодировку, есть на сайте и автоматический режим.
Дизайн простой, без лишних наворотов и рекламы, которая мешает нормальной работе с ресурсом.
Перейти на сайт Fox Tools
- Вводим исходный текст в верхнее поле.
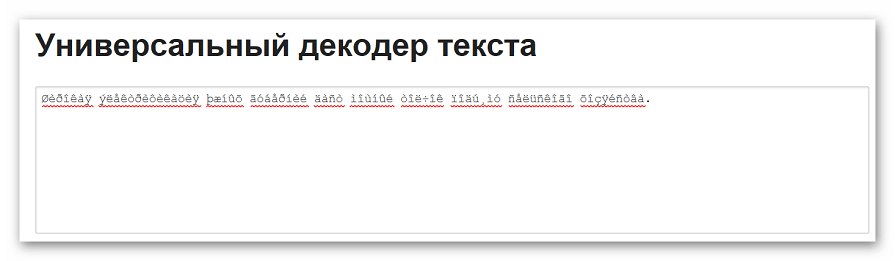
- Выбираем начальную и конечную кодировку. Если данные параметры неизвестны, оставляем настройки по умолчанию.
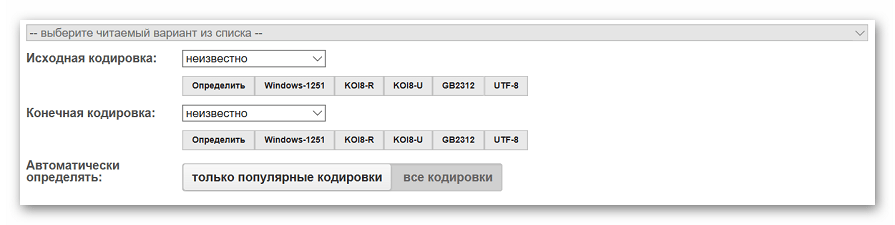
- После завершения настроек нажимаем на кнопку «Отправить».

- Из списка под начальным текстом выбираем читабельный вариант и щелкаем на него.
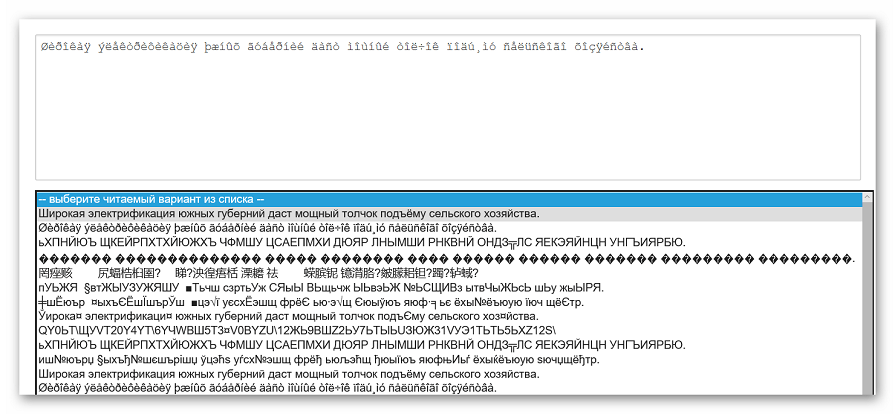
- Вновь нажимаем на кнопку «Отправить».
- Преобразованный текст будет отображаться в поле «Результат».

Несмотря на то, что сайт якобы распознает кодировку в автоматическом режиме, пользователю все равно приходится выбирать понятный результат в ручном режиме. Из-за данной особенности куда проще воспользоваться описанными выше способами.
Читайте также: Выбор и изменение кодировки в Microsoft Word
Рассмотренный сайты позволяют всего в несколько кликов преобразовать непонятный набор символов в читаемый текст. Самым практичным оказался ресурс Универсальный декодер — он безошибочно перевел большинство зашифрованных текстов.
 Мы рады, что смогли помочь Вам в решении проблемы. Задайте свой вопрос в комментариях, подробно расписав суть проблемы. Наши специалисты постараются ответить максимально быстро.
Мы рады, что смогли помочь Вам в решении проблемы. Задайте свой вопрос в комментариях, подробно расписав суть проблемы. Наши специалисты постараются ответить максимально быстро. Помогла ли вам эта статья?
Да Нетlumpics.ru
Подбор читаемой кодировки с кириллицей онлайн
Пришло мне письмо с не читаемой кириллической кодировкой и встал вопрос о декодирование этой абракадабры в читаемый набор символов. Для этих целей под Windows есть хороший софт, который не раз помогал в таких случаях – Shtirlitz IV 4.01. Но в этот раз он не выдала даже приблизительно читаемый текст.
После непродолжительного googling around был найден Универсальный декодер кириллицы.
Вкратце о возможностях:
- Визуальный подбор исходной кодировки
- Программа проверяет максимум 4725 вариантов из двух и трех перекодировок: если имело место многократное перекодирование вроде koi8(utf(cp1251(utf))), оно не будет распознано или проверено. Если в вашем случае предполагается многократное преобразование – рекомендую воспользоваться выше упомянутым Shtirlitz, он иногда правильно понимает многократное преобразование.
- Если части текста закодированы в разных кодировках, программа сможет распознать только одну часть за раз.
- На преобразуемый текст есть ограничения – 20 Кб
Что сразу понравилось, так это комбобокс Выберите кодировку, в котором перечислен примерный вид исходного текста, т.е. не надо гадать какая правильная исходная и желаемая кодировка, а можно определить примерно по внешней последовательности символов.
Если в списке не было найдено примерно совпавшей кодировки можно воспользоваться Испробовать все комбинации. После нажатия кнопки OK страница перезагрузиться и в выпадающем списке можно будет просмотреть список всех возможных преобразований, среди них я нашел более-менее читаемый текст для своего случая. Правда, некоторые символы не были правильно преобразованы, но текст стал разборчивым и можно было понять смысл письма.
Есть возможность и полностью управляемого декодирования с выбором исходной кодировки, предполагаемой кодировкой и методом кодирования символов (Content-Transfer-Encoding для MIME).
Еще варианты:
proft.me
Лучшие онлайн-сервисы и программы для декодирования текстов
Текстовые данные, с которыми пользователь работает находясь за монитором, изначально хранятся в числовом виде. Для их преобразования применяется кодирование. В разных системах нумерации одним и тем же числовым значениям соответствуют разные последовательности букв, цифр и иных символов.
Иногда пользователь, скачавший документ или открывший веб-страницу обнаруживает, что вместо привычного текста документ заполнен непонятными символами и «кракозябрами». Это означает, что документ сохранен его автором в нерелевантной настройкам текущего пользователя кодировке. Чтобы корректно прочитать документ, потребуется декодировать его одним из методов – использовав онлайн-сервис, специальное приложение или поменяв настройки в Word.
Стоит отметить, что стандарты в разных странах не всегда идентичны, и если российский пользователь, применяющий в Word обычную кириллическую кодировку, пытается открыть документ созданный, например, жителем Южной Америки (и сохраненный в стандартном для его страны формате), он не получит нужного отображения содержимого документа. Ряд кодировок подходит только для отображения символов определенного языка.
Лучшие сайты
Рассмотрим наиболее эффективные конвертеры символов, работающие с привычной кириллицей. Большинство из них можно использовать в режиме «по умолчанию» благодаря встроенному алгоритму расшифровки, но при надобности можно применять ручные настройки.
Универсальный декодер — конвертер кириллицы
Этот сервис наиболее популярен среди пользователей рунета. Найти можно по адресу 2cyr.com. Для работы с ним нужно скопировать подлежащий декодированию текст и вставить в предназначенное для этого поле. Нужно разместить копируемый отрывок так, чтобы уже на его первой строке встречались «кракозябры». Если пользователь хочет, чтобы сервис распознал кодировку автоматически, нужно указать это в выпадающем списке выбора. Но возможна и ручная настройка с указанием нужного типа. Закодированный фрагмент будет доступен в блоке «Результат».
Однако сервис, при всей своей простоте и возможности выбора, имеет и ограничения. Если поместить в поле текст объемом более 100 Кб сервис не сможет обработать его, так что длинные фрагменты придется декодировать по кусочкам.
Декодер Артемия Лебедева
Этот дешифратор работает со всеми кодировками с которыми может столкнуться пользователь, работающий с кириллицей.
Декодер Лебедева включает в себя простой и сложный (с дополнительными настройками) режимы работы. В режиме «Сложно» отображается не только исходный текст, но и преобразованный. Также можно выбрать кодировку, в которую требуется перевести текст, из выпадающего списка. Декодированный фрагмент доступен для прочтения и копирования в правом блоке.
Fox Tools
Как и в случае с предыдущими, пользователю Fox Tools предоставляется возможность выбрать конечный результат. Сервис может работать и в режиме «по умолчанию», применяющемся в случае неизвестной желаемой кодировки, но тогда все равно придется выбирать вручную вариант результирующего текста, наиболее отвечающий его цели. Сервис имеет весьма простой и понятный дизайн интерфейса, что делает его подходящим для людей с низким уровнем компьютерной грамотности.
Translit.net
Сервис Translit, напротив, не отличается лаконичностью внешнего вида, но принцип работы с ним такой же, как и у других онлайн-декодеров. Нужно ввести текст и вручную установить желаемые настройки.
Программа Штирлиц
Это приложение предназначено для работы с русскоязычными кодировками. Текст в нее можно копировать как из буфера обмена, так и из содержимого текстового файла. Приложение реализует проверку разных схем перекодировки; если схема не обеспечивает корректного отображения всех русскоязычных слов, она отбрасывается и проверяется следующая. Также в программе Штирлиц можно создать авторскую кодовую схему и применять ее при работе с текстом, подвергшимся многократным перекодировкам.
Чтобы обрабатывать сразу несколько файлов параллельно, необходимо открывать каждый из них в индивидуальном окне программы.
Декодер русских текстов TCODE
Этот программный продукт используется для восстановления русскоязычного текста, подвергшегося некоторым модификациям при передаче файла. Сюда относится и неподходящая кодировка. Решающее значение имеют первые 25 слов – они должны состоять из символов первой части ASCII. Скачать декодер можно на официальном сайте.
Как раскодировать текст в word
Поскольку этот редактор имеет огромную популярность и в нем создается большое число текстовых файлов, пользователи часто сталкиваются с некорректным отображением символов или невозможностью открыть фрагмент с неподходящей кодировкой.
Если документ Word открылся в режиме ограниченной функциональности, нужно убрать ее. Если вместо кириллицы или латиницы по-прежнему отображаются непонятные знаки, нужно указать правильную кодировку в настройках программы. Для этого жмем кнопку «Файл» (или “Office”, в ранней версии), затем кнопку «Параметры» и выбираем «Дополнительно». Во вкладке «Общие» ставим флажок в настройке «Подтверждать преобразование формата». Подтверждаем изменения, закрываем программу, а затем опять открываем файл в ней. В окне «Преобразование» выбираем «Кодированный текст». Выбираем нужный вариант, ориентируясь на пример отображаемого теста в превью.
Как определить кодировку
Существует несколько способов определения:
- В MS Word при открытии файла: если набор отличается от СР1251, программа предложит выбрать одну из подходящих с наибольшей вероятностью кодировок. Оценить, насколько они подходят, можно по превью образца текста;
- В программе KWrite. В нее надо загрузить документ с расширением .txt и воспользоваться настройками в меню «Кодирование»;
- Открыть файл в браузере Mozilla Firefox. При корректном отображении в меню «Вид» ищем кодировку. Искомый вариант – тот, напротив которого стоит флажок. Если содержимое отобразилось с искажениями, проверяем разные варианты в меню «Дополнительно»;
- Для работающих с Unix подойдет программа Enca.
composs.ru