Семантический поиск: мифы и реальность. Семантический поиск
мифы и реальность / Хабр
Например, при вводе в строку поиска «Столица Франции», оба метода дают один и то же правильный ответ: «Париж». Кроме того, большинство запросов, которые мы вбиваем в строку поиска в виде аббревиатур, дают те же результаты, если вводить термин полностью. Очевидно, что тут что-то не так. Всем известно, что семантические технологии способны на многое, но почему? И как они работают? Ознакомившись с этой статьей, вы узнаете, что на самом деле, мы просто-напросто задаем не те вопросы. Ошибка заключается в том, что семантические поисковые системы, по сути, обладают аналогичной с Google строкой ввода, которая позволяет нам вводить запросы в свободной форме. Поэтому мы вводим запросы так, как привыкли – в простейшей форме. Мы никогда не будем вводить в строку поиска «Какой актер снимался в фильмах «Криминальное чтиво» и «Лихорадка субботним вечером»? или «Какие два сенатора США брали взятки от иностранных компаний?». Мы всегда вбиваем простые фразы, но сила семантического поиска не в этом. Чтобы понять, как все работает, предлагаем рассмотреть несколько технологий семантического поиска от Google, SearchMonkey, Powerset и Freebase.
Какую проблему мы пытаемся решить?
Первая сложность возникает, когда семантический поиск начинают считать решением всевозможных задач – от современной системы поиска, где доминирует Google, до задач, которые нельзя решить вычислительным путем. Все еще более усложняется тем, что в настоящее время есть лишь несколько областей знания, где семантический поиск действительно справляется лучше — это сложные запросы о выводах и рассуждениях о сложных системах данных.
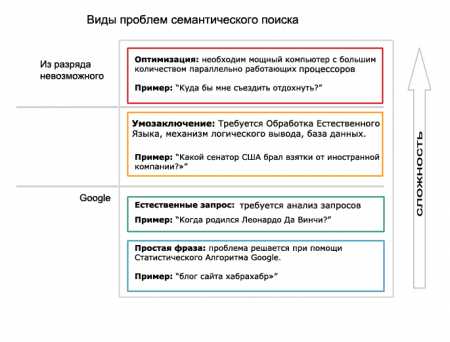
Перед тем, как рассмотреть задачи, с которыми легко справляется семантический поиск, рассмотрим самые сложные задачи. Существуют требующие вычисления задачи, которые не имеют ничего общего с пониманием семантики слова. На ранней стадии существования Семантического Веба бытовало мнение, что с его помощью мы сможем решать даже сверхсложные задачи, но, к сожалению это не так. Есть пределы того, что мы можем вычислить, и есть класс задач с огромным числом возможных решений, и мы не можем волшебным способом решить эти задачи только потому, что представили информацию в RDF.
Но есть также и пласт задач, с которыми семантический веб справляется великолепно. Мы решали их при помощи тематической базы данных. Но не стоит забывать, что семантические технологии помогают нам отыскать тематическую информацию, рассредоточенную по всей сети – потому для нас нет ничего удивительного в том, что семантические поисковые системы превзойдут тематические запросы.
Обзор семантических поисковых систем
Суть семантического поиска не только в вопросах, задаваемых нами. По причине того, что веб – это набор неструктурированных HTML-страниц, в основе семантического поиска лежит еще и базовая информация. Самой четкой и понятной из всех мы нашли Freebase – семантическая база данных. Freebase работает не только через текстовый поиск, а что наиболее важно, и через — MQL (Metaweb Query Language). MQL это почти тот же JSON (текстовый формат обмена данными), но с более широкими возможностями. С его помощью вы можете составить любой запрос в Freebase и ответом будет тот же запрос, но уже со вставленными результатами поиска.

Powerset, по сути, это тематическая база данных, которая работает с определенной структурированной информацией. С другой стороны есть Google, который в первую очередь ориентируется на статистическую частоту запросов и почти не принимает во внимание семантику. Вызывает интерес новая система SearchMonkey от Yahoo! Эта система ничего не добавляет к найденным результатам, но использует семантические аннотации для более полного, интерактивного и полезного пользовательского интерфейса.
Компании Hakia и Powerset явно работают с максимальной отдачей. Они пытаются создать подобные Freebase структуры, а потом по топовым результатам провести поиск на естественном языке. Отличие в том, что Hakia (как и другие) использует технологию для поиска по всей сети, а Powerset замкнул свой поиск на Wikipedia.
Что общего и где различия?
В связи с этим появляется вопрос: «Какие из этих технологий схожи, а какие кардинально отличаются?» Давайте начнем с простого. SearchMonkey ничем не отличается от Google и любой другой поисковой системы, т.к. суть у них одна, а разница присутствует лишь во внешнем виде. Сервис SearchMonkey хорош тем, что позволят издателям представить результаты поиска в наилучшем виде.
Что же касается Hakia, Powerset и Freebase, то тут ситуация иная. На первый взгляд они совершенно разные: Hakia в поиске использует весь веб, Powerset – лишь Wikipedia и Freebase, а Freebase обладает двумя поисковыми интерфейсами: поисковая строка и язык поиска. Но существует одна проблема: естественный язык не имеет ничего общего с репрезентативностью базовой информации.
Дело в том, что все технологии семантического поиска позволяют пользователям вбивать произвольные сложные вопросы, а затем интерпретируют их и применяют к имеющимся базам данных. Hakia, Powerset, Freebase такими базами являются, и все они обладают системой автоматической обработки естественного языка, которая «переводит» вопрос на стандартный запрос, понятный для базы.
Чтобы понять, как это все устроено, представьте Freebase и его язык поиска MQL. В отличие от естественного языка, который позволяет задать вопрос разными способами, MQL двусмысленности не предполагает. Этот JSON-подобный язык позволяет пользователям формулировать четкие запросы для поиска в базе Freebase. То, что Powerset позволяет строить вопросы на естественном языке, еще не значит, что Powerset не является базой данных. Powerset – это база, т.к. в ее основе лежит поисковая строка Freebase. Отличие Freebase от Powerset заключается в подходах к поиску и способам предоставления его результатов.
Назад в будущее: все дело в пользовательском интерфейсе
Возможно, самым важным моментом в семантическом поиске является пользовательский интерфейс. В Powerset поняли, что в нем должна быть отражена семантика. После поиска в Powerset, контекстуальный гаджет, который знаком с семантикой результатов, поможет пользователю завершить весь процесс.
Слабым местом Powerset является интерфейс. Поисковая строка, с которой знакомы все, кто когда-либо что-то искал в сети, устарела. Слишком простой интерфейс Powerset и Hakia не приносит им пользы, но и не слишком отражается на Freebase, который не позиционирует себя, как поисковая система.
Вспомните недавний старт Powerset. Компания предоставила лучший способ для поиска в одном из самых мощных источников информации в сети — в Wikipedia. Но что говорят критики? Можно ли назвать эту систему главным конкурентом Google? Ответ однозначен — нет.
А что если на Powerset наложены некие ограничения по поиску? Что если вместо поисковой строки использовался другой интерфейс или компания сказала пользователям не искать то, что они легко могут найти в Google? Может, новые компании должны улучшить алгоритм поиска, который существует уже более 10 лет? В любом случае, любые идеи должны быть нацелены на то, чтобы решить задачи, которые не может на сегодняшний день решить Google.
Заключение
Семантический поиск – это технология будущего, поставившая перед собой слишком высокие цели. Все мы думали, что он поможет свергнуть Google и предоставить наиболее качественные результаты поиска. Оба эти утверждения оказались ложными. Правда в том, что семантический поиск — явление многофакторное, и он поможет нам решать те задачи, которые мы не можем решить сейчас: сложные, логически обоснованные запросы, которые сплошь и рядом встречаются в сети.
Для того, чтобы технологии семантического поиска заняли свою нишу на рынке, компаниям необходимо пересмотреть поставленные цели и улучшить пользовательский интерфейс. Поисковая строка не актуальна и сулит убытки, т.к. она ассоциируется с простыми вопросами, с которыми легко справляется Google. Разработчикам необходимо предложить совершенно новый интерфейс, чтобы пользователи смогли полностью ощутить всю мощь семантического поиска.
habr.com
Эволюция семантического поиска Google и его влияние на SEO
Скорее всего, вы неоднократно слышали выражение «семантический поиск». Однако знаете ли вы, какую роль он играет в поисковой оптимизации? В этой статье мы расскажем все, что вам нужно знать о семантическом поиске и SEO. Только на первый взгляд это звучит сложно — на самом деле, все гораздо проще, чем кажется.
Crowd.com объясняет это понятие следующим образом:
«В двух словах, целью семантического поиска является расширение стандартного словарного значения слова или фразы для того, чтобы понять намерение пользователя в рамках конкретного контекста. На основе изучения прошлых результатов и создания связей между сущностями (entites) поисковая система может вывести реальный ответ на запрос пользователя, а не просто предоставить десяток ссылок на выбор».
Несколько примеров семантического поиска
Ниже представлено несколько стандартных характеристик поиска, с которыми мы сталкиваемся ежедневно.
Часто задаваемые запросы и результаты:
Автоисправление опечаток:
Графическое представление информации:
Как появился семантический поиск?
Семантический поиск возник из семантической сети, которая строится на онтологиях. В области наук об информации и вычислительной технике онтология изначально означает информационную структуру и набор фактов, представляющих собой систему знания.
Техническое определение онтологии немного сложнее:
«В контексте компьютерных и информационных наук онтология определяет набор изобразительных примитивов, с помощью которых можно моделировать область знаний или дискурса. Изобразительные примитивы — это, как правило, классы (или наборы), атрибуты (или свойства) и взаимосвязи (или отношения между членами класса). Определение репрезентативных примитивов включает в себя информацию об их значении и ограничениях, касающихся логики их применения. В контексте систем баз данных, онтология может рассматриваться как уровень абстракции моделей данных, аналогичный иерархическим и реляционным моделям, но предназначенный для моделирования знаний о людях, их атрибутах и взаимоотношениях с другими лицами.
Онтология, как правило, более точно представлена в языках, которые позволяют абстрагироваться от структур данных и стратегии внедрения; на практике языки онтологий ближе по выразительным средствам логике первого порядка, чем языки, используемые для моделирования баз данных. По этой причине онтологии относят к семантическому уровню, в то время как в системе баз данных присутствуют модели данных логического или физического уровня. Из-за их независимости от моделей данных более низкого уровня, онтологии используются для интеграции разнородных баз данных, что делает возможным взаимодействие между разрозненными системами, и конкретизируя интерфейсы для независимых, основанных на знаниях сервисах.
Среди технологических средств семантических веб-стандартов онтологии представляют собой отдельный слой. В настоящее время существуют стандартные языки, а также коммерческие и открытые инструменты для создания онтологий и работы с ними».
Другими словами, онтология позволяет анализировать конкретные запросы и группы запросов, основываясь на отношениях взаимосвязанных факторов.
В качестве примера приведем диаграмму со схематичным обозначением онтологии:
Семантическая сеть использует взаимодействие информационных множеств, характеристик и отношений для упорядочения огромного количества информации, наполняющей интернет.
W3C, Консорциум Всемирной Сети, где впервые использовался семантический поиск, объясняет это понятие так:
«Семантическая сеть представляет собой общую структуру, которая позволяет делиться информацией и повторно использовать ее вне границ приложений, организаций и соцсетей».
Как все это связано с поиском?
Семантика имеет дело с языком программирования. Компьютеры подчиняются специфическим семантическим правилам заданного языка программирования, выполняя конкретные процессы и соблюдая определенные команды.
Семантические характеристики веб-страницы — это что-то вроде мета-тегов. С ростом популярности семантических сетей увеличилось и количество мета-данных для поисковых систем. Почти все, что связано с запросами или сайтами, может считаться частью семантической области, имеющей отношение к результатам поиска.
Семантический поиск зависит как от семантической разметки веб-сайтов, так и от огромного количества семантической информации, которое она за собой влечет.
Как давно существует семантический поиск?
Теория семантического поиска уходит корнями к 2003 году и статье Р.Гуха и др., о IBM, Стэнфорде и Консорциуме Всемирной Сети.
Тогда был продемонстрирован принцип работы семантического поиска.
Переход от теории к практике занял некоторое время, но 10 лет спустя, в 2013 году, произошел первый крупный прорыв в области семантического поиска для рядовых пользователей. Возможно, вы об этом слышали — речь идет об обновлении алгоритма поиска «Колибри».
Алгоритм «Колибри» обеспечивал точность и быстроту поиска. Многие SEO-специалисты знают, что с этим алгоритмом «разговорный поиск» был применен в действии.
Однако алгоритм «Колибри» значил куда больше, чем просто разговорные запросы. «Колибри» уделяет особое внимание каждому слову в тексте запроса, гарантируя обработку запроса целиком, а не через значение отдельных слов.
Из этого объяснения, данного Дэнни Салливаном, понятно, что с внедрением «Колибри» поиск вышел далеко за пределы границ ключевых слов в более широкую область семантических показателей.
Какие факторы используются в механизме работы поисковых систем?
Фактически неизвестно, какой именно комплекс факторов используют поисковые системы для предоставления наиболее точных ответов. И все-таки известно, что Google применяет набор из более чем 200 ранжированных факторов.
Семантический поиск позволяет более глобально смотреть на поисковый запрос, используя множество показателей для предоставления наиболее точных результатов.
Последние достижения в компьютерном обучении (machine learning) также позволили усовершенствовать возможности семантического поиска, обеспечивая его независимое функционирование и непрерывное улучшение, а также способность предоставлять более релевантные ответы на запрос.
Чем семантический поиск лучше модели поиска по ключевым словам?
Ответ в том, что семантический поиск куда более точен.
Если бы поисковые системы просто предоставляли ответы на основе ключевых слов, вам не понравились бы полученные результаты. Самые лучшие результаты могут быть получены только с учетом семантических факторов веб-страницы.
Скажем, вам необходимо найти «детали газонокосилок». В соответствии с несемантическими запросами, вы получили бы адреса страниц, просто содержащих слова «детали газонокосилок».
Происходит же иначе — показываются только те результаты поиска для запроса «детали газонокосилок», которые подходят вам территориально.
Это всего один пример семантического поиска в действии, но на самом деле их гораздо больше.
Самый первый результат поиска для запроса «детали газонокосилок» не содержит это словосочетание вообще, даже при просмотре исходного кода страницы.
Так действует семантическая поисковая оптимизация, предоставляя результат, основанный на множестве факторов, а не только на трех словах запроса. Как это происходит?
Как вы уже поняли, поиск — это гораздо больше, чем напечатанные вами слова:
- Поиск связан с миллионами других людей, которые пишут те же слова запроса.
- Он связан с машинным обучением Google.
- С сезонными тенденциями относительно данного запроса.
- С поисковыми трендами в конкретном месте проживания: ведь если мы живем в таком месте, где можно только починить старые детали газонокосилок, результаты получились бы другими.
- А что, если пользователь залогинился в Google во время поиска, и Google как-то узнал, что этот пользователь — упрямый мастер-самоучка, который уже в прошлом ремонтировал свою газонокосилку. Будут ли результаты отличаться в таком случае?
Действительно, все это учитывается в процессе поиска.
Cемантическтй предоставляет результат, основанный на множестве факторов, а не только на словах запроса
Твитнуть цитату
Google собирал данные по запросу «детали газонокосилок» более чем 10 лет. В результате стало известно, что интерес к этому запросу варьируется в зависимости от времени года, количества осадков и начала сезона.
Также стало известно, что граждане США, Ирландии и Канады чаще всего ищут «детали газонокосилок», а также что люди чаще ищут фирменные детали газонокосилок, подходящие для конкретной модели.
Обнаружилось также, что «ремонт газонокосилок» ищут реже, чем «детали газонокосилок». Кстати, с 2005 интерес к поиску «ремонта газонокосилок» возрос по сравнению с поиском «деталей»: сейчас больше пользователей ищут первое, чем второе.
Google знает все это, и намного больше.
Каждый байт данных обрабатывается так, что поисковик индексирует и предоставляет самые лучшие результаты для небольшого невинного запроса «детали газонокосилок».
Вот почему семантический поиск настолько мощен. Вместо того, чтобы просто получать набор сайтов с выбранным вами ключевым словом, вы получите наиболее подходящие сайты для конкретной ситуации.
Самое большое преимущество семантического поиска
Возможно, самое главное достоинство семантического поиска заключается в том, что он позволяет принять во внимание намерение пользователя и информацию о нем.
Самые лучшие результаты — не те, которые содержат ключевые слова, оптимизированный заголовок h2 и хорошо обработанный тег title.
Наоборот, наиболее релевантная страница — это та, которая соответствует намерению пользователя. Как в примере с деталями газонокосилок: Google понимает, что большинство ищет не детали газонокосилок, которые сложно достать — люди хотят починить свою газонокосилку, предпочтительно профессионалом, который знает, какую деталь нужно заказать и как это сделать.
Основываясь на агрегированной информации миллионов пользователей, алгоритм поисковой системы научился понимать, чего они действительно хотят.
Поисковые системы собирают огромное количество информации с каждого запроса. Например, в 2012 году доктор Питер Дж. Мейерс из сообщества Моз объяснил, что Google и другие поисковики используют данные по кликабельности страниц выдачи и времени нахождения на сайте для предоставления наилучших результатов поиска. Благодаря консоли поиска в Google и Google Analytics мы можем также получить кое-какие из этих данных.
Все эти и другие данные сейчас включены в процесс поиска Google, предоставляя ответы на вопросы, спрогнозированные решения проблем и результаты поиска, которые дают вам больше, чем вы ожидали.
По мере развития семантического поиска мы можем ожидать еще более продвинутых результатов.
Дэвид Эмерланд представляет это так:
«Что, если вы берете телефон, запускаете голосовой поиск и еще до того, как вы что-то произносите, система начинает загружать адреса ресторанов, предлагающих пиццу, предполагая, что вы голодны? Это как если бы ваш близкий друг знал, что, скажем, по четвергам, если вы находитесь в этом районе и если вы без машины, вы любите побаловать себя пиццей на обед».
Впечатляет, не так ли?
Что со всем этим делать?
Вся информация о семантическом поиске может помочь вам чувствовать себя умными и продвинутыми, но она не принесет абсолютно никакой пользы, если вы не знаете, как ее применить.
Если вы применяете последние разработки в области SEO и контент-маркетинга, то у вас и так все в порядке. Если же вы до сих пор занимаетесь заполнением сайтов ключевыми словами в духе 2006-го, то вам следует изменить направление.
Ниже представлен небольшой список того, что вам нужно сделать в плане улучшения конверсии за счет семантического поиска:
1. Меньше задумывайтесь о ключевых словах. Имеют ли ключевые слова значение? Конечно, но не стоит на них зацикливаться. Если у вас есть целевой контент, у вас все в порядке.
2. Убедитесь, что каждый фрагмент контента, который вы производите, имеет четкую направленность. Поисковые системы создавались для идентификации сути вашего контента, поэтому каждый абзац контента должен быть сфокусирован на одной теме с явным смыслом.
3. Создавайте высококачественный контент. Только и всего.
4. Старайтесь понять намерение пользователя: оно значит гораздо больше в эпоху семантического поиска. Намерение пользователя — это суть создания контента, который должен удовлетворять ему, а не набору ключевых слов. Помните: семантический поиск — это идентификация намерения пользователя.
5. Не перегружайте сайт ключевыми словами. Это известный факт, но его стоит повторить: перенасыщение ключевыми словами не работает.
6. Используйте структурированную разметку данных: это усилит поисковую оптимизацию в эпоху семантического поиска.
7. Сфокусируйтесь на длинных поисковых запросах запросах. Даже если одно ключевое слово и не имеет особого значения, составные ключевые запросы до сих пор существенны. Убедитесь, что ваш контент адаптирован под такие запросы.
Вместо заключения
Основной вывод таков: дайте пользователю лучший опыт взаимодействия из всех возможных.
В поисковой оптимизации все основывается на опыте взаимодействия — чем он лучше, тем выше ваш сайт в результатах поиска, особенно в эпоху семантического поиска.
Это стоит знать о SEO — в конце концов, это настоящее и будущее интернет-поиска. К счастью, применить эти знания на практике это не так уж сложно.
Высоких вам конверсий!
По материалам crazyegg.com, image source flikr.com
16-02-2016
lpgenerator.ru
Семантический поиск — Википедия
Семантический поиск — способ и технология поиска информации, основанная на использовании контекстного (смыслового) значения запрашиваемых фраз, вместо словарных значений отдельных слов или выражений при поисковом запросе. Улучшение результатов поиска при обработке запросов достигается за счет более точной интерпретации поисковых намерений пользователя.
Для осуществления семантического поиска в Сети (или в каких-либо системах с ограниченным доступом пользователей) применяются специальные технологии. При семантическом поиске учитывается информационный контекст, местонахождение и цель поиска пользователя, словесные вариации, синонимы, обобщенные и специализированные запросы, язык запроса, а также другие особенности, позволяющие получить соответствующий результат[1].
Технология семантического поиска рассматривается как дополнение, либо альтернатива традиционным видам поиска информации. Ряд крупных поисковых систем, таких как Google и Bing, используют некоторые элементы семантического поиска, не являясь таковыми в чистом виде.
История
Семантический поиск возник из семантической сети, которая строится на онтологиях. В области наук об информации и вычислительной технике онтология изначально означает информационную структуру и набор фактов, представляющих собой систему знания. Теория семантического поиска уходит корнями к 2003 году и статье Р.Гуха и др., о IBM, Стэнфорде и Консорциуме Всемирной паутины[2]. Тогда был продемонстрирован принцип работы семантического поиска.
С ростом популярности семантических сетей увеличилось и количество метаданных для поисковых систем. Почти все, что связано с запросами или сайтами, может считаться частью семантической области, имеющей отношение к результатам поиска.
Семантический поиск зависит как от семантической разметки веб-сайтов, так и от огромного количества семантической информации, которое она за собой влечет. В 2013 году первым крупным прорывом в технологиях семантического поиска стал алгоритм «Колибри»[3]. С этим алгоритмом был применен «разговорный поиск».
Видео по теме
Атрибуты, определяющие семантический поиск
Атрибуты семантического поиска (отличающие его от не семантического поиска) не обязательно являются его преимуществами. Некоторые из атрибутов могут повысить точность поиска за счет использования большого количества времени (или других ресурсов). Соответственно, эти десять атрибутов являются лишь характерными чертами семантического поиска, дающими преимущество только в идеальных условиях[4].
1. Обработка морфологических вариаций.
2. Обработка синонимов с правильными значениями.
3. Обработка обобщений.
4. Обработка концептуального множества.
5. Обработка базы знаний.
6. Обработка запросов и вопросов, заданных простым языком.
7. Возможность определения непрерывного параграфа и наиболее соответствующего предложения.
8. Возможность к адаптации и органичному прогрессу.
9. Способность работать, не полагаясь на данные статистики, поведение пользователей и других искусственных средств.
10. Способность обнаруживать результаты своей собственной деятельности.
Семантический поиск в поисковых системах
Факторы, учитываемые поисковыми системами
Семантический поиск осуществляет не только анализ контекста, но и других факторов. Умные поисковые системы учитывают целый ряд факторов для того, чтобы получить наиболее соответствующие и подходящие поисковые запросы, включая:
1. Текущие тенденции
Если выборы президента только что закончились, и кто-то ищет информацию: «Кто стал новым президентом?», семантический поиск должен понять запрос и дать соответствующие результаты, основанные на текущих тенденциях и новостях.
2. Местонахождение пользователя
Если человек ввел запрос «Какая сейчас температура?», семантическая поисковая система должна предоставить результаты, основанные на месте его нахождения в момент запроса. Например, для ростовского жителя результатом запроса будут данные о температуре воздуха в городе Ростове-на-Дону.
3. Цель поиска
Семантический поиск основывается на выдаче подходящих результатов, основанных на цели поиска пользователя, а не определенных слов, использованных при обращении к поисковой системе.
4. Вариации слов в семантическом поиске
Семантический поиск должен учитывать лингвистические особенности запроса (падеж, число и время) и предлагать подходящие результаты для всех семантических вариаций слов, то есть видеть различия между близкими по написанию словами. Например, в таких словах как «техника» (транспортные средства или должность в род. падеже), «техники» (методики или должность во мн.ч.), «техник» (должность или методики во мн.ч), смысл часто меняется при переходе от единственного числа к множественному.
5. Синонимы
Семантические поисковые системы должны понимать синонимы и давать более или менее похожие результаты на любые синонимичные слова, запрашиваемые пользователем. Например, при запросах «наивысший пик» или «наибольший пик» ответ должен быть одинаковым.
6. Общие и специализированные запросы
Семантические поисковые системы должны обнаруживать связь между общими и специализированными запросами и предоставлять соответствующие результаты. Например, в сети существует информация как по общим вопросам здравоохранения, так и информация про «диабет». Если кто-то запрашивает информацию о состоянии здоровья, то семантический поиск должен предложить ссылки на оба источника, несмотря на то что в статье про диабет отсутствует упоминание слов «здоровье» или «здравоохранение».
7. Концептуальное множество
Это подмножество контекстной информации в семантическом поиске. Семантический поиск понимается как концепция запроса для получения соответствующих результатов. Например, запрос «проблемы дорожного движения в Москве» может выдать соответствующие результаты, включая такие, как «узкие дороги», «машины с мигалками», «ремонт дорог и строительство эстакад», «оставленный на обочинах автотранспорт» и т. д., так как с широкой концептуальной точки зрения, все это приводит к проблемам дорожного движения.
8. Простой язык при запросах
Не каждый человек - технический гуру, и не много людей знают, что именно нужно искать, чтобы получить нужный ответ. Большинство пользователей просто спросят, например, «Время во Владивостоке», на что большинство поисковых систем дадут ссылки на сайты где упоминаются «время» и «Владивосток». Умные поисковые системы сразу выдадут текущее время во Владивостоке.
9. Зависимость между значением фразы и использованными в ней словами
Конкретные слова в словосочетаниях и фразах или их порядок могут изменить истинное значение всего запроса. Например, запрос «Система приобретет новые активы в различных секторах» коренным образом отличается от запроса «Система приобретет новые очертания в различных секторах». В первом случае речь может идти о компании АФК «Система» и ее стратегии по покупке активов, вероятнее всего, в частном и государственном секторах. Второй вариант, вероятнее всего, говорит об изменении экономической модели и ее отражении на практике.
Преимущества семантического поиска в Google
Google не является в чистом виде семантической поисковой системой, хотя и использует некоторые элементы семантического поиска. Семантическая поисковая оптимизация, предоставляет результат, основанный на множестве факторов, а не только на значении слов запроса.
Результат семантического поиска связан:
1. С миллионами других людей, которые пишут те же слова запроса.
2. С машинным обучением Google.
3. С временными, сезонными и погодными тенденциями относительно данного запроса.
4. С поисковыми тенденциями в конкретном месте проживания.
Каждый байт данных обрабатывается таким образом, что поисковая система индексирует и предоставляет самые подходящие результаты к самому простому запросу. Основываясь на агрегированной информации миллионов пользователей, алгоритм поисковой системы умеет понимать, чего они действительно хотят. Поисковые системы собирают огромное количество информации с каждого запроса. Google и другие поисковики используют данные по кликабельности страниц выдачи и времени нахождения на сайте для предоставления наилучших результатов поиска. Благодаря консоли поиска в Google и Google Analytics можно также получить некоторые из этих данных[3].
Обзор семантических поисковых систем
Суть семантического поиска заключается не только в форме вопросов, заданных поисковой системе. Поскольку, веб — это набор неструктурированных HTML-страниц, в основе семантического поиска также лежит и базовая информация. Одной из самых интуитивных и наиболее точных семантических баз данных считается Freebase. Freebase работает не только через текстовый поиск, а что наиболее важно, и через — MQL (Metaweb Query Language). MQL работает подобно JSON (текстовый формат обмена данными), но обладает более широкими возможностями. С его помощью можно составить любой запрос в Freebase, ответом на который будет тот же запрос, но уже с прикрепленными результатами поиска. Powerset, по сути, это тематическая база данных, которая работает с определенной структурированной информацией[5].
Google, в первую очередь, ориентируется на статистическую частоту запросов и почти не принимает во внимание семантику. Особо стоит отметить новую систему SearchMonkey от Yahoo! Эта система ничего не добавляет к найденным результатам, но использует семантические аннотации для более полного, интерактивного и полезного пользовательского интерфейса. Компании Hakia и Powerset постоянно работают над улучшением возможностей поиска. Их стратегия включает создание структур подобных Freebase с дальнейшим проведением поиска по наиболее релевантным результатам на естественном языке. Основное отличие заключается в том, что Hakia (как и другие) использует технологию для поиска по всей сети, а Powerset замкнул свой поиск только на Wikipedia[5].
Проблемы семантического поиска
Поисковые системы сталкиваются с огромным числом проблем при осуществлении поиска по семантике. Первой из них является определение того, что конкретно имел в виду пользователь, когда вводил поисковый запрос, то есть существование различных значений слова или фразы в различных контекстах.
Семантический поиск не сможет помочь при решении задач, не решаемых вычислительным путем.
Существуют требующие вычисления задачи, которые не имеют ничего общего с пониманием семантики слова. На ранней стадии существования Семантического Веба считалось, что с его помощью можно решать даже сверхсложные задачи, однако, достигнуть высокого уровня все еще не удалось. Существуют пределы того, что можно вычислить, и имеется категория задач с огромным числом возможных решений, которые невозможно решить только на основе представления информации в RDF.
Кроме того, существует пласт задач, с которыми семантический веб справляется великолепно. Он решается при помощи тематической базы данных. Семантические технологии помогают отыскать тематическую информацию, рассредоточенную по всей сети, следовательно, семантические поисковые системы часто превосходят тематические запросы[6].
Примечания
wikipedia.green
Семантический поиск и его влияние на SEO продвижение
Привет 👋 Друзья! Большинство компаний, уже знают, что SEO является неотъемлемой частью их онлайн-работы, даже если они не понимают полностью, как это действует. А происходит это благодаря грамотно организованному семантическому поиску.
Семантический поиск и его влияние на SEO продвижение

SEO продвижение существует уже несколько десятилетий, но только с начала 2000-х годов поисковой гигант Google предпринял меры, чтобы сосредоточить фокус SEO на опыте пользователей, а не на конкретных формулах, которые позволяют высоко поднять сайт в результатах поиска.
С этой целью Google сосредоточился на быстрой реакции на поисковые онлайн-запросы и выдаче точных результатов даже с учетом ошибок в словах, неполных фраз или плохо сформулированных запросов.
В прошлом SEO основывалась на жесткой структуре ключевых слов. Веб-мастера и SEO-специалисты проводили обширное исследование ключевиков и делали все возможное, чтобы заполнить целевыми поисковыми фразами все уголки своих сайтов. При написании SEO-текстов ключевые слова или фразы часто использовались на странных и неестественных для них позициях, делая контент трудночитаемым. Иногда написанный текст не имел никакого отношения к ключевым словам.
Как итог, SEO-специалисты писали только для поисковых роботов, а пользователи часто оставались разочарованными нерелевантными результатами выдачи по своим запросам. Тем не менее все изменилось, и мы перешли от буквализма к семантике.
Обновления алгоритмов Google
С 2002 года Google начал внедрять обновления алгоритмов и требований для сортировки и ранжирования веб-сайтов. Веб-мастера больше не могли использовать кликбейты и забивать контент ключевыми словами. Теперь они должны были создавать релевантные тексты, полезные для пользователя, если хотели, чтобы их сайты занимали высокие позиции в результатах поиска.
Тренд на создание дружественного пользователям контента продолжился в 2013 году, когда Google представил обновление алгоритма Hummingbird.
Алгоритм Hummingbird изменил то, как Google интерпретировал поисковые запросы пользователей. Вместо того чтобы искать одинаковые слова и дословные фразы, Google начал фокусироваться на намерении поискового запроса.
Слова и фразы больше не должны были совпадать точно, Google теперь искал сайты, соответствующие идее поискового запроса. По сути, Google начал понимать смысл, который был заложен в написанном тексте и проверял его соответствие заголовку и ключевым словам встречающимся в контенте.
Это обновление Hummingbird было создано после осознания того, что в современном быстро развивающемся обществе, где пользователи не хотят печатать длинные, правильно сформулированные поисковые запросы, они по-прежнему ожидают мгновенных релевантных результатов.
Основной компонент обновления Hummingbird от Google называется RankBrain.
RankBrain — искусственный интеллект (ИИ), который позволяет машинам поискового алгоритма Google лучше интерпретировать сложные поисковые запросы и намерения пользователей при поиске.
И именно понятие намерения является основой того, что мы называем семантическим поиском.
Голос в текст
Ряд технологических инноваций помог распространению этой тенденции. Наиболее известной является функция «Голос в текст» — или голосовой поиск.
С функцией преобразования голоса в текст появилась возможность проговорить ключевое слово или поисковую фразу в панели поиска Google на своем смартфоне, а мобильная платформа Google будет переводить произносимые слова в набранный текст.
В результате все больше пользователей начали применять голосовой поиск. При выполнении поискового запроса они фактически используют ту же терминологию и фразы, как в обычном разговоре. Люди говорят и печатают по-разному, и Google признал это.
Обновление алгоритма Hummingbird превратило опыт пользователей из жесткого механического процесса в нечто более семантическое.
Плюсы семантических SEO-запросов
Какой положительный эффект принесла смена того, как люди ищут и как ранжируются результаты?
1. Простой интуитивный поиск
После всех изменений, которые происходили «за кулисами», пользователи привыкли к быстрому интуитивному поисковому опыту, который дает релевантные результаты. Раньше пользователям приходилось забивать в строку поиска несколько различных вариантов ключевых слов, если первоначальные результаты выдачи их не устраивали.
В то же время SEO-специалисты должны были точно определять, какие фразы будут использовать клиенты и писать контент для сайта, включающий именно эти фразы (независимо от того, насколько неестественно они выглядели).
Семантический поиск изменил это, всё меньше фокусируясь на конкретных словах или фразах и больше — на поисковом намерении пользователя. И оптимизаторам сегодня приходиться изменять свои стратегии с учетом этих изменений.
2. Лучший контент
Цель каждого обновления алгоритма — улучшить поисковый опыт пользователей. После обновлений Hummingbird появились результаты поиска, которые считались наиболее релевантными для ненапечатанного намерения пользователя.
Теперь люди вводят поисковые запросы, похожие на то, как они говорят. Google использует ИИ (искусственный интеллект) для поиска сайтов на основе этого нового синтаксиса поискового запроса.
При снижении акцента на конкретные ключевые слова и формальную структуру фразы, контент на веб-сайтах теперь должен быть более высокого качества. Часто размещенные ключевые слова, странные и не естественные ключевые фразы, больше не привлекают Google и пользователей.
Чтобы создавать высококачественный и продающий контент, авторы должны проводить более тщательные исследования по темам и писать так, чтобы текст был легко читаемым, привлекательным и ценным.
3. Качественные результаты
Благодаря семантическому поиску первые страницы результатов стали наполнены высококачественным контентом, который точно отвечает на исходный запрос.
Во многом это было достигнуто с помощью «расширенных ответов». Google собирает ответы на поисковые запросы и показывает на страницах результатов поиска (SERP) таким образом, чтобы пользователю не нужно было нажимать на URL сайта для просмотра контента. Пользователь получает короткие сниппеты релевантного контента.
Хотя сниппеты и являются наиболее часто отображаемой формой «расширенных ответов», диаграммы, таблицы, слайдеры, карты и документы, отображающие корректную релевантную информацию, также могут отображаться в результатах поиска.
Когда пользователи получают почти мгновенно ответы, которые их устраивают — это им нравится. Именно по этому такие монстры как Google и Яндекс, постоянно конкурируют между собой, и улучшают качество поисковой выдачи, пытаясь этим привлечь в свою сеть максимальное количество пользователей.
Цель использования семантической SEO состоит в том, чтобы создать наибольшую ценность для людей и мгновенно решить их проблемы. SEO-специалисты теперь должны тратить больше времени на оптимизацию контента своего сайта так, чтобы он представлял ценность для пользователей.
Поскольку ключевые слова больше не в центре внимания, специалистам SEO стало сложнее определить поисковое намерение пользователя. Теперь для того чтобы быть первым в поисковой выдаче, нужно использовать в тексте смысловые слова LSI.
5. Меньше внимания ключам
Как вы уже поняли, семантический поиск уделяет все меньше внимания ключевым словам. Но исследование ключевых слов по-прежнему важно для оценки популярности определенных поисковых запросов. Однако ключевые слова, которые раньше использовали для таргетинга, больше не являются краеугольным камнем всей вашей SEO-стратегии.
Прошли те дни, когда копирайтерам нужно было использовать в текстах точные вхождения ключевых слов и несколько раз прописывать эти ключи по тексту. Теперь эти слова помогают лишь ориентироваться поисковым роботам в определении темы написанного контента, но сам текст должен быть максимально сосредоточен на том, чего действительно хочет пользователь.
6. Больше гибкости
Отказ от точного совпадения ключевых фраз заставляет оптимизаторов применять гораздо большую гибкость в создании контента. Альтернативные формулировки и синонимы, появляющиеся в результатах поиска, позволяют контенту сайта быть более креативным, уникальным, настоящим и в конечном счете полезным.
Авторы контента теперь больше не обязаны строить текст так, чтобы просто протолкнуть определенные ключевые слова.
Новый семантический подход к SEO полезен как пользователям, так и SEO-специалистам, которые оптимизируют и пишут контент для сайтов. Теперь они лучше понимают друг друга, что улучшило общий опыт работы в интернете.
Оптимизирован ли ваш сайт для семантического поиска? Если нет, есть вероятность, что он не появится или скоро перестанет появляться на верхних строчках результатов выдачи для ваших ключевых слов или фраз.
Google и Яндекс уделяют все больше внимания поведенческим факторам, и если вы все еще занимаетесь «олдскульной» поисковой оптимизацией, то ваш сайт никогда не обгонит конкурентов.
Оптимизация сайта и работа с обновлениями алгоритмов Google и Яндекс требуют времени, терпения и усилий, а также первоклассных знаний в области SEO для объединения всего вашего контента в единую маркетинговую стратегию.
Обучение продвижению сайтов
Для тех кто хочет научиться выводить сайты в ТОП 10 поисковых систем Яндекс и Google, я организовал онлайн-уроки по SEO-оптимизации (смотри видео ниже). Все свои интернет-проекты я вывел на посещаемость более 1000 человек в сутки и могу научить этому Вас. Кому интересно обращайтесь!
На этом сегодня всё, всем удачи и до новых встреч!
hozyindachi.ru
Семантический поиск — WiKi
Семантический поиск — способ и технология поиска информации, основанная на использовании контекстного (смыслового) значения запрашиваемых фраз, вместо словарных значений отдельных слов или выражений при поисковом запросе. Улучшение результатов поиска при обработке запросов достигается за счет более точной интерпретации поисковых намерений пользователя.
Для осуществления семантического поиска в Сети (или в каких-либо системах с ограниченным доступом пользователей) применяются специальные технологии. При семантическом поиске учитывается информационный контекст, местонахождение и цель поиска пользователя, словесные вариации, синонимы, обобщенные и специализированные запросы, язык запроса, а также другие особенности, позволяющие получить соответствующий результат[1].
Технология семантического поиска рассматривается как дополнение, либо альтернатива традиционным видам поиска информации. Ряд крупных поисковых систем, таких как Google и Bing, используют некоторые элементы семантического поиска, не являясь таковыми в чистом виде.
Цель семантического поиска - определять особенности пользователя и предоставлять ему наиболее релевантные результаты.
Атрибуты семантического поиска (отличающие его от не семантического поиска) не обязательно являются его преимуществами. Некоторые из атрибутов могут повысить точность поиска за счет использования большого количества времени (или других ресурсов). Соответственно, эти десять атрибутов являются лишь характерными чертами семантического поиска, дающими преимущество только в идеальных условиях[4].
1. Обработка морфологических вариаций.
2. Обработка синонимов с правильными значениями.
3. Обработка обобщений.
4. Обработка концептуального множества.
5. Обработка базы знаний.
6. Обработка запросов и вопросов, заданных простым языком.
7. Возможность определения непрерывного параграфа и наиболее соответствующего предложения.
8. Возможность к адаптации и органичному прогрессу.
9. Способность работать, не полагаясь на данные статистики, поведение пользователей и других искусственных средств.
10. Способность обнаруживать результаты своей собственной деятельности.
Факторы, учитываемые поисковыми системами
Семантический поиск осуществляет не только анализ контекста, но и других факторов. Умные поисковые системы учитывают целый ряд факторов для того, чтобы получить наиболее соответствующие и подходящие поисковые запросы, включая:
1. Текущие тенденции
Если выборы президента только что закончились, и кто-то ищет информацию: «Кто стал новым президентом?», семантический поиск должен понять запрос и дать соответствующие результаты, основанные на текущих тенденциях и новостях.
2. Местонахождение пользователя
Если человек ввел запрос «Какая сейчас температура?», семантическая поисковая система должна предоставить результаты, основанные на месте его нахождения в момент запроса. Например, для ростовского жителя результатом запроса будут данные о температуре воздуха в городе Ростове-на-Дону.
3. Цель поиска
Семантический поиск основывается на выдаче подходящих результатов, основанных на цели поиска пользователя, а не определенных слов, использованных при обращении к поисковой системе.
4. Вариации слов в семантическом поиске
Семантический поиск должен учитывать лингвистические особенности запроса (падеж, число и время) и предлагать подходящие результаты для всех семантических вариаций слов, то есть видеть различия между близкими по написанию словами. Например, в таких словах как «техника» (транспортные средства или должность в род. падеже), «техники» (методики или должность во мн.ч.), «техник» (должность или методики во мн.ч), смысл часто меняется при переходе от единственного числа к множественному.
5. Синонимы
Семантические поисковые системы должны понимать синонимы и давать более или менее похожие результаты на любые синонимичные слова, запрашиваемые пользователем. Например, при запросах «наивысший пик» или «наибольший пик» ответ должен быть одинаковым.
6. Общие и специализированные запросы
Семантические поисковые системы должны обнаруживать связь между общими и специализированными запросами и предоставлять соответствующие результаты. Например, в сети существует информация как по общим вопросам здравоохранения, так и информация про «диабет». Если кто-то запрашивает информацию о состоянии здоровья, то семантический поиск должен предложить ссылки на оба источника, несмотря на то что в статье про диабет отсутствует упоминание слов «здоровье» или «здравоохранение».
7. Концептуальное множество
Это подмножество контекстной информации в семантическом поиске. Семантический поиск понимается как концепция запроса для получения соответствующих результатов. Например, запрос «проблемы дорожного движения в Москве» может выдать соответствующие результаты, включая такие, как «узкие дороги», «машины с мигалками», «ремонт дорог и строительство эстакад», «оставленный на обочинах автотранспорт» и т. д., так как с широкой концептуальной точки зрения, все это приводит к проблемам дорожного движения.
8. Простой язык при запросах
Не каждый человек - технический гуру, и не много людей знают, что именно нужно искать, чтобы получить нужный ответ. Большинство пользователей просто спросят, например, «Время во Владивостоке», на что большинство поисковых систем дадут ссылки на сайты где упоминаются «время» и «Владивосток». Умные поисковые системы сразу выдадут текущее время во Владивостоке.
9. Зависимость между значением фразы и использованными в ней словами
Конкретные слова в словосочетаниях и фразах или их порядок могут изменить истинное значение всего запроса. Например, запрос «Система приобретет новые активы в различных секторах» коренным образом отличается от запроса «Система приобретет новые очертания в различных секторах». В первом случае речь может идти о компании АФК «Система» и ее стратегии по покупке активов, вероятнее всего, в частном и государственном секторах. Второй вариант, вероятнее всего, говорит об изменении экономической модели и ее отражении на практике.
Преимущества семантического поиска в Google
Google не является в чистом виде семантической поисковой системой, хотя и использует некоторые элементы семантического поиска. Семантическая поисковая оптимизация, предоставляет результат, основанный на множестве факторов, а не только на значении слов запроса.
Результат семантического поиска связан:
1. С миллионами других людей, которые пишут те же слова запроса.
2. С машинным обучением Google.
3. С временными, сезонными и погодными тенденциями относительно данного запроса.
4. С поисковыми тенденциями в конкретном месте проживания.
Каждый байт данных обрабатывается таким образом, что поисковая система индексирует и предоставляет самые подходящие результаты к самому простому запросу.
Основываясь на агрегированной информации миллионов пользователей, алгоритм поисковой системы умеет понимать, чего они действительно хотят. Поисковые системы собирают огромное количество информации с каждого запроса. Google и другие поисковики используют данные по кликабельности страниц выдачи и времени нахождения на сайте для предоставления наилучших результатов поиска. Благодаря консоли поиска в Google и Google Analytics можно также получить некоторые из этих данных[3].
Суть семантического поиска заключается не только в форме вопросов, заданных поисковой системе. Поскольку, веб — это набор неструктурированных HTML-страниц, в основе семантического поиска также лежит и базовая информация.
Одной из самых интуитивных и наиболее точных семантических баз данных считается Freebase. Freebase работает не только через текстовый поиск, а что наиболее важно, и через — MQL (Metaweb Query Language). MQL работает подобно JSON (текстовый формат обмена данными), но обладает более широкими возможностями. С его помощью можно составить любой запрос в Freebase, ответом на который будет тот же запрос, но уже с прикрепленными результатами поиска. Powerset, по сути, это тематическая база данных, которая работает с определенной структурированной информацией[5].
Google, в первую очередь, ориентируется на статистическую частоту запросов и почти не принимает во внимание семантику. Особо стоит отметить новую систему SearchMonkey от Yahoo! Эта система ничего не добавляет к найденным результатам, но использует семантические аннотации для более полного, интерактивного и полезного пользовательского интерфейса.
Компании Hakia и Powerset постоянно работают над улучшением возможностей поиска. Их стратегия включает создание структур подобных Freebase с дальнейшим проведением поиска по наиболее релевантным результатам на естественном языке. Основное отличие заключается в том, что Hakia (как и другие) использует технологию для поиска по всей сети, а Powerset замкнул свой поиск только на Wikipedia[5].
Поисковые системы сталкиваются с огромным числом проблем при осуществлении поиска по семантике. Первой из них является определение того, что конкретно имел в виду пользователь, когда вводил поисковый запрос, то есть существование различных значений слова или фразы в различных контекстах.
Семантический поиск не сможет помочь при решении задач, не решаемых вычислительным путем.
Существуют требующие вычисления задачи, которые не имеют ничего общего с пониманием семантики слова. На ранней стадии существования Семантического Веба считалось, что с его помощью можно решать даже сверхсложные задачи, однако, достигнуть высокого уровня все еще не удалось. Существуют пределы того, что можно вычислить, и имеется категория задач с огромным числом возможных решений, которые невозможно решить только на основе представления информации в RDF.
Кроме того, существует пласт задач, с которыми семантический веб справляется великолепно. Он решается при помощи тематической базы данных. Семантические технологии помогают отыскать тематическую информацию, рассредоточенную по всей сети, следовательно, семантические поисковые системы часто превосходят тематические запросы[6].
ru-wiki.org
Семантический поиск
Одна из наших предыдущих статей была посвящена социальному поиску от Yahoo! и одной из новых поисковых систем AnooX, заявившей о выпуске собственной версии социального поиска. В продолжение темы поиска мы предлагаем Вашему вниманию статью, темой которой является другой вид поиска – семантический.
В настоящее время в поисковых системах используется релевантная модель оценки соответствия исследуемого документа поисковому запросу. Данная модель практически не справляется с решением задач распознавания и поиска омонимов (грамматических, и, особенно, - лексических), синонимов и многозначных слов. Это обусловлено тем, что в основу релевантной модели поиска заложен лингвистический подход и ряд оценочных синтетических критериев (таких как положение слов на странице), а перечисленные выше языковые артефакты не могут быть распознаны без понимания смысла поискового запроса. Семантические поисковые системы пытаются привнести такой смысл в результаты запросов поиска, представленные в контекстном формате. В настоящее время семантические механизмы представляются провайдерами рекламы. В рамках статьи мы предлагаем рассмотреть данное явление с точки зрения их использования в бесплатных поисковых системах.
Crystal Semantics является разработчиком Textonomy Advance, первого в мире семантического механизма. Данный поисковый инструмент способен использовать знания человека, с которыми алгоритмы других программ не могут работать. Уникальная семантическая сеть от Crystal Semantics понимает смысл слов, выражений, а также устанавливает лингвистические связи между ними.
Textonomy, в отличии от существующих поисковых технологий, основу которых представляют статистические алгоритмы, использует лингвистические правила для определения семантической зависимости между словами и контекстом, в котором они встречаются. Функционирование Textonomy Advanced Engine напрямую связано с различными словарями и энциклопедиями, представленными различными источниками.
Семантический механизм
Семантический механизм стал результатом долгих научно-исследовательских работ (в течение 8 лет) в области поисковой лингвистики и $8-миллионных вложений в этот процесс. Все началось с разработки классификационной системы, предназначенной для данных, собранных для первого издания Кембриджской энциклопедии, позднее система получила широкое распространение среди многих других энциклопедий разных издательств, например, Cambridge University Press, Penguin Book.
В то же время вся база данных принадлежала издательству Cambridge University Press, но в 1997 году она была продана голландскому электронному издательству AND, которое начало ее разработку для интерактивного использования. В течение последующих 4 лет классификационная система была преобразована в «глобальную модель данных», предполагающую несколько приложений к классификации документов и поисковым технологиям. Когда компания AND в 2001 вышла из бизнеса, вся база данных была приобретена компанией Crystal Reference Systems, созданной с целью развития глобальной модели данных и ее основного понятия «семантического механизма». Это одна из крупнейших семантических систем, постоянно развивающихся под наблюдением профессора Кристалла и его высококвалифицированной редакторской команды.
Чтобы лучше понять поисковую лингвистику, используемую Crystal Semantics, и ответить на вопрос, почему в теории возможно большее, нежели на практике, предлагаем обсудить это вместе.
Булевый поиск и поиск с использованием Wildcard-символов
Булевый поиск – это комбинация элементов, позволяющих включать и исключать из поисковых результатов документы, содержащие определенные слова. Это достигается с помощью булевых операторов and, not, or, near.
Вот как используются операторы: •And или знак плюс (+) – в описании должны присутствовать 2 и более элемента или фразы; And – это оператор, заданный по умолчанию. •Or - один из элементов должен быть в описании. •Not или знак минус (-) – из поиска исключается один элемент или фраза.
Булевый поиск представляет собой одну из самых простых поисковых программ сравнения. Ярким примером булевого поиска служит использование любой крупной поисковой системы (Google, Yahoo) со множеством слов. Это предполагает использование оператора And для поиска всех элементов. Например, введем запрос «покупка плазменного телевизора онлайн», из этого будет следовать, что поиску подлежат все слова, соответствующие запросу. Все страницы, где есть слова купить, плазменный, телевизор и онлайн будут представлены в результатах поиска.
Другой пример. Если пользователь хочет исключить из поиска один из элементов, например, «купить плазменный телевизор онлайн – Sony», поисковый алгоритм воспримет это следующим образом: все релевантные результаты, имеющие слова купить, плазменный, телевизор и онлайн, будут включены в результаты поиска, а вот страницы, на которых есть слово Sony, будут исключены.
Очень редко поисковая система не поддерживает булевый поиск. В основном, булевые операторы представлены во всех системах и функционируют автоматически.
Поиск с использованием Wildcard-символов
Многие современные поисковые системы мира поддерживают поиск с использованием Wildcard-символов. Зачастую Wildcard-символы в виде астериска (*) или знака вопроса (?) используются для замены букв при написании.
Поиск с использованием Wildcard-символов предполагает поиск элементов, которые подходят словам с пропущенной буквой, например, слова text или test можно искать следующим образом: с помощью te*t или te?t.
Поиск с расстоянием
Некоторые поисковые системы поддерживают поиск слов, которые находятся на определенном удалении от элементов запроса. Поиск с расстоянием - поиск, при котором пользователь указывает, на каком расстоянии между собой должны располагаться ключевые слова в документе. Для осуществления данного вида поиска необходимо в конце фразы использовать тильду (~). Например, чтобы задать поиск слов теплица и углерод на расстоянии 10 слов друг от друга, в строку запроса нужно ввести следующее: теплица углерод ~10.
Неточный поиск
Возможно, не все знакомы с понятием «неточный поиск». В процессе неточного поиска определяются страницы, которые могут быть релевантными аргументу поиску, даже если аргумент неточно соответствует желаемой информации. Неточный поиск осуществляется посредством «Программы неточного сравнения», которая демонстрирует список результатов, составленный на основе некоторого сходства слова-аргумента с написанным вариантом. Наиболее точные и релевантные совпадения можно будет найти в начале всего списка результатов поиска. Иногда присутствует оценка относительной релевантности (в процентах) результатов поиска.
Программа неточного сравнения может выполнять функции корректора правописания. Например, пользователь ввел слово Misissippi неверно в Yahoo! или Google (обе системы используют данную программу), список найденных совпадений будет сопровождаться вопросом «Вы имели в виду Mississippi?». В программе представлены слова с альтернативным написанием и слова, имеющие одинаковое звучание, но разное написание. Программа неточного сравнения корректирует общие опечатки, а также ошибки, допущенные в процессе оптического распознавания знаков (OCR) печатных документов.
Обычно программа неточного сравнения представляет помимо релевантных совпадений и нерелевантные. Как правило, это происходит, если слово имеет много значений, одно из которых может оказаться релевантным запросу. Если у пользователя только смутное представление о том, что ему нужно найти, то следует ориентироваться по оценке относительной релевантности (у нерелевантных совпадений оценка будет низкой).
С точки зрения научных исследований, неточный поиск представляет больше возможностей, чем его точный аналог. Неточный поиск широко применяется при исследовании малоизвестных, специфических работ и работ на иностранном языке, правильное написание названий которых не известно. Данный вид поиска также используется для определения местоположения объекта, информация о котором не точна или ее не достаточно.
Используя неточный поиск, пользователю нужно внести в строку поиска все варианты написания искомого слова (множественное/единственное число, а также варианты неправильного написания).
Поиск по контексту
В оффлайн-разговоре собеседники без труда понимают друг друга, легко определяя нужное значение многозначного слова по контексту. Поиск по контексту представляет собой онлайн-попытку определять нужное значение слова в зависимости от окружающих его слов (контекста). Именно поиск по контексту лежит в основе системы Crystal Semantics’ Textonomy. Данный вид поиска имеет частичное сходство с неточным поиском, а отличие в том, что поиск по контексту предусматривает оценку содержания всей страницы в целом, а не отдельного слова.
Однако релевантные результаты поиска продолжают оставаться актуальной проблемой для поисковых систем. Именно по причине некорректной информации многие предпочитают не использовать Интернет с этой целью. Даже поддерживая такие программы, как Булевый поиск, Неточный поиск и даже поиск с использованием Wildcard-символов, поисковые системы не могут достичь совершенства в поиске. Многие продолжают считать, что поиск шагнет вперед только с развитием Поиска по контексту.
По информации www.seochat.com
www.seonews.ru
Семантический поиск Википедия
Семантический поиск — способ и технология поиска информации, основанная на использовании контекстного (смыслового) значения запрашиваемых фраз, вместо словарных значений отдельных слов или выражений при поисковом запросе. Улучшение результатов поиска при обработке запросов достигается за счет более точной интерпретации поисковых намерений пользователя.
Для осуществления семантического поиска в Сети (или в каких-либо системах с ограниченным доступом пользователей) применяются специальные технологии. При семантическом поиске учитывается информационный контекст, местонахождение и цель поиска пользователя, словесные вариации, синонимы, обобщенные и специализированные запросы, язык запроса, а также другие особенности, позволяющие получить соответствующий результат[1].
Технология семантического поиска рассматривается как дополнение, либо альтернатива традиционным видам поиска информации. Ряд крупных поисковых систем, таких как Google и Bing, используют некоторые элементы семантического поиска, не являясь таковыми в чистом виде.
Цель семантического поиска - определять особенности пользователя и предоставлять ему наиболее релевантные результаты.
История
Семантический поиск возник из семантической сети, которая строится на онтологиях. В области наук об информации и вычислительной технике онтология изначально означает информационную структуру и набор фактов, представляющих собой систему знания. Теория семантического поиска уходит корнями к 2003 году и статье Р.Гуха и др., о IBM, Стэнфорде и Консорциуме Всемирной паутины[2]. Тогда был продемонстрирован принцип работы семантического поиска.
С ростом популярности семантических сетей увеличилось и количество метаданных для поисковых систем. Почти все, что связано с запросами или сайтами, может считаться частью семантической области, имеющей отношение к результатам поиска.
Семантический поиск зависит как от семантической разметки веб-сайтов, так и от огромного количества семантической информации, которое она за собой влечет. В 2013 году первым крупным прорывом в технологиях семантического поиска стал алгоритм «Колибри»[3]. С этим алгоритмом был применен «разговорный поиск».
Атрибуты, определяющие семантический поиск
Атрибуты семантического поиска (отличающие его от не семантического поиска) не обязательно являются его преимуществами. Некоторые из атрибутов могут повысить точность поиска за счет использования большого количества времени (или других ресурсов). Соответственно, эти десять атрибутов являются лишь характерными чертами семантического поиска, дающими преимущество только в идеальных условиях[4].
1. Обработка морфологических вариаций.
2. Обработка синонимов с правильными значениями.
3. Обработка обобщений.
4. Обработка концептуального множества.
5. Обработка базы знаний.
6. Обработка запросов и вопросов, заданных простым языком.
7. Возможность определения непрерывного параграфа и наиболее соответствующего предложения.
8. Возможность к адаптации и органичному прогрессу.
9. Способность работать, не полагаясь на данные статистики, поведение пользователей и других искусственных средств.
10. Способность обнаруживать результаты своей собственной деятельности.
Семантический поиск в поисковых системах
Факторы, учитываемые поисковыми системами
Семантический поиск осуществляет не только анализ контекста, но и других факторов. Умные поисковые системы учитывают целый ряд факторов для того, чтобы получить наиболее соответствующие и подходящие поисковые запросы, включая:
1. Текущие тенденции
Если выборы президента только что закончились, и кто-то ищет информацию: «Кто стал новым президентом?», семантический поиск должен понять запрос и дать соответствующие результаты, основанные на текущих тенденциях и новостях.
2. Местонахождение пользователя
Если человек ввел запрос «Какая сейчас температура?», семантическая поисковая система должна предоставить результаты, основанные на месте его нахождения в момент запроса. Например, для ростовского жителя результатом запроса будут данные о температуре воздуха в городе Ростове-на-Дону.
3. Цель поиска
Семантический поиск основывается на выдаче подходящих результатов, основанных на цели поиска пользователя, а не определенных слов, использованных при обращении к поисковой системе.
4. Вариации слов в семантическом поиске
Семантический поиск должен учитывать лингвистические особенности запроса (падеж, число и время) и предлагать подходящие результаты для всех семантических вариаций слов, то есть видеть различия между близкими по написанию словами. Например, в таких словах как «техника» (транспортные средства или должность в род. падеже), «техники» (методики или должность во мн.ч.), «техник» (должность или методики во мн.ч), смысл часто меняется при переходе от единственного числа к множественному.
5. Синонимы
Семантические поисковые системы должны понимать синонимы и давать более или менее похожие результаты на любые синонимичные слова, запрашиваемые пользователем. Например, при запросах «наивысший пик» или «наибольший пик» ответ должен быть одинаковым.
6. Общие и специализированные запросы
Семантические поисковые системы должны обнаруживать связь между общими и специализированными запросами и предоставлять соответствующие результаты. Например, в сети существует информация как по общим вопросам здравоохранения, так и информация про «диабет». Если кто-то запрашивает информацию о состоянии здоровья, то семантический поиск должен предложить ссылки на оба источника, несмотря на то что в статье про диабет отсутствует упоминание слов «здоровье» или «здравоохранение».
7. Концептуальное множество
Это подмножество контекстной информации в семантическом поиске. Семантический поиск понимается как концепция запроса для получения соответствующих результатов. Например, запрос «проблемы дорожного движения в Москве» может выдать соответствующие результаты, включая такие, как «узкие дороги», «машины с мигалками», «ремонт дорог и строительство эстакад», «оставленный на обочинах автотранспорт» и т. д., так как с широкой концептуальной точки зрения, все это приводит к проблемам дорожного движения.
8. Простой язык при запросах
Не каждый человек - технический гуру, и не много людей знают, что именно нужно искать, чтобы получить нужный ответ. Большинство пользователей просто спросят, например, «Время во Владивостоке», на что большинство поисковых систем дадут ссылки на сайты где упоминаются «время» и «Владивосток». Умные поисковые системы сразу выдадут текущее время во Владивостоке.
9. Зависимость между значением фразы и использованными в ней словами
Конкретные слова в словосочетаниях и фразах или их порядок могут изменить истинное значение всего запроса. Например, запрос «Система приобретет новые активы в различных секторах» коренным образом отличается от запроса «Система приобретет новые очертания в различных секторах». В первом случае речь может идти о компании АФК «Система» и ее стратегии по покупке активов, вероятнее всего, в частном и государственном секторах. Второй вариант, вероятнее всего, говорит об изменении экономической модели и ее отражении на практике.
Преимущества семантического поиска в Google
Google не является в чистом виде семантической поисковой системой, хотя и использует некоторые элементы семантического поиска. Семантическая поисковая оптимизация, предоставляет результат, основанный на множестве факторов, а не только на значении слов запроса.
Результат семантического поиска связан:
1. С миллионами других людей, которые пишут те же слова запроса.
2. С машинным обучением Google.
3. С временными, сезонными и погодными тенденциями относительно данного запроса.
4. С поисковыми тенденциями в конкретном месте проживания.
Каждый байт данных обрабатывается таким образом, что поисковая система индексирует и предоставляет самые подходящие результаты к самому простому запросу.
Основываясь на агрегированной информации миллионов пользователей, алгоритм поисковой системы умеет понимать, чего они действительно хотят. Поисковые системы собирают огромное количество информации с каждого запроса. Google и другие поисковики используют данные по кликабельности страниц выдачи и времени нахождения на сайте для предоставления наилучших результатов поиска. Благодаря консоли поиска в Google и Google Analytics можно также получить некоторые из этих данных[3].
Обзор семантических поисковых систем
Суть семантического поиска заключается не только в форме вопросов, заданных поисковой системе. Поскольку, веб — это набор неструктурированных HTML-страниц, в основе семантического поиска также лежит и базовая информация.
Одной из самых интуитивных и наиболее точных семантических баз данных считается Freebase. Freebase работает не только через текстовый поиск, а что наиболее важно, и через — MQL (Metaweb Query Language). MQL работает подобно JSON (текстовый формат обмена данными), но обладает более широкими возможностями. С его помощью можно составить любой запрос в Freebase, ответом на который будет тот же запрос, но уже с прикрепленными результатами поиска. Powerset, по сути, это тематическая база данных, которая работает с определенной структурированной информацией[5].
Google, в первую очередь, ориентируется на статистическую частоту запросов и почти не принимает во внимание семантику. Особо стоит отметить новую систему SearchMonkey от Yahoo! Эта система ничего не добавляет к найденным результатам, но использует семантические аннотации для более полного, интерактивного и полезного пользовательского интерфейса.
Компании Hakia и Powerset постоянно работают над улучшением возможностей поиска. Их стратегия включает создание структур подобных Freebase с дальнейшим проведением поиска по наиболее релевантным результатам на естественном языке. Основное отличие заключается в том, что Hakia (как и другие) использует технологию для поиска по всей сети, а Powerset замкнул свой поиск только на Wikipedia[5].
Проблемы семантического поиска
Поисковые системы сталкиваются с огромным числом проблем при осуществлении поиска по семантике. Первой из них является определение того, что конкретно имел в виду пользователь, когда вводил поисковый запрос, то есть существование различных значений слова или фразы в различных контекстах.
Семантический поиск не сможет помочь при решении задач, не решаемых вычислительным путем.
Существуют требующие вычисления задачи, которые не имеют ничего общего с пониманием семантики слова. На ранней стадии существования Семантического Веба считалось, что с его помощью можно решать даже сверхсложные задачи, однако, достигнуть высокого уровня все еще не удалось. Существуют пределы того, что можно вычислить, и имеется категория задач с огромным числом возможных решений, которые невозможно решить только на основе представления информации в RDF.
Кроме того, существует пласт задач, с которыми семантический веб справляется великолепно. Он решается при помощи тематической базы данных. Семантические технологии помогают отыскать тематическую информацию, рассредоточенную по всей сети, следовательно, семантические поисковые системы часто превосходят тематические запросы[6].
Примечания
wikiredia.ru