Содержание
Классификатор автомобилей
| Марка | 1 класс | 2 класс | 3 класс | 3+ класс |
|---|---|---|---|---|
| ALFA ROMEO | 147, 159, Mito, Brera, Giulietta | |||
| ACURA | ILX, RLX, TSX, TL | MDX, RDX, ZDX | ||
| AUDI | A1, A2, A3, TT | A4, A5, A6, A7, Q3, Q5, Allroad | A8, S8, R8, Q7 | |
| BMW | 1, Z3, Z4 | 3, 4, 5, X1, X2, X3 | 6, 7, X4, X5, X6, GT | X7 |
| BENTLEY | Arnage, Continental GT, Flying Spur, Mulsanne | |||
| CADILLAC | ATS, BLS | CTS, STS | Escalade, SRX | Escalade ESV |
| CHEVROLET | Spark, Aveo, Cobalt, Cruze, Lacetti, Lanos | Camaro, Malibu, Niva, Orlando | Captiva, Trailblaizer | Tahoe, Van, Silverado |
| CHRYSLER | Crossfire, PT Cruiser | 200, 300, Sebring | Town & Country, Voyager | |
| CITROEN | C1, C2, C3, C4, DS3, Berlingo | C4 Picasso, C4 Aircross, Grand C4, C-crosser C5, C6, C8 | Jumpi Multispace | |
| CHERY | Tiggo 4 | Tiggo 7, Tiggo 8 | ||
| CHANGAN | CS 35, CS 55 | |||
| DODGE | Caliber | Challenger, Charger | Caravan, Journey | |
| FIAT | 500, Albea, Barchetta, Bravo, Linea, Punto, Stilo | Freemont, Panorama, Sedici | ||
| FORD | Fiesta, Ka, Focus, Fusion | C-max, Mondeo, Kuga, Maverick, Mustang | Explorer, Galaxy, S-max | F150, F250, F350 |
| GENESIS | G70, G80 | GV70, GV80, G90 | G90L | |
| GEELY | Coolray | Atlas | ||
| HONDA | Civic, Jazz | Accord, Crosstour, CR-V, Legend | Pilot | Odyssey |
| HYUNDAI | Getz, Accent, Elantra, Solaris, Veloster | I40, NF, Sonata, Santa Fe, IX35, Tucson | Equus, IX55 | Starex, H-1 |
| HUMMER | h2, h3, h4 | |||
| HAVAL | H5, H6, Jolion | F7, F7x, H9 | ||
| INFINITY | G25, Q50 (G), Q60 (G), Q70 (M), QX50 (EX) | QX60, QX70 (FX) | ||
| JAGUAR | E-type, F-type, S-type, XF | XK, XJ | ||
| JEEP | Compass, Cherokee, Liberty, Wrangler | Grand Cherokee, Wrangler Unlimited | ||
| KIA | Picanto, Cerato, Ceed, Rio, Spectra, Venga | Carens, Magentis, Opirus, Optima, K5, Soul, Sportage | Mohave, Sorento, Quoris | |
| LAND ROVER | Evoque, Freelander | Discovery, Defender, Range Rover RR Sport | Range Rover | |
| LEXUS | CT | ES, NX, GS, IS | LS, GX, RX | LX |
| MASERATI | Chibli, Granturismo, Quattroporte | |||
| MAYBACH | 57, 62, Guard | |||
| MINI | Cooper | Countryman, Paceman | ||
| MAZDA | 2, 3, MX-5, RX-8 | 5, 6, CX-5 | CX-7, CX-9 | BT-50 |
| MERCEDES | Smart, A, B, SLK | C, CLA, E, GLK | GL, M, R, S, SL, SLS | Vito, Viano, G-класс |
| MITSUBISHI | Colt, I-Miev, Carisma, Lancer | Galant, ASX, Outlander | Pajero | L200 |
| NISSAN | Micra, Almera, Note, Tiida | GTR, Primera, Teana, Juke, Qashqai, X-trail | Murano, Pathfinder | Navara, Patrol |
| OPEL | Corsa, Astra | Insignia, Meriva, Vectra, Antara, Mokka, Zafira | ||
| PEUGEOT | 107, 206, 207, 208, 301, 307, 308 | 407, 408, 508, 605, RCZ, Partner, 3008, 4007, 4008 | Boxer, Traveller | |
| PORSCHE | Boxster, Cayman, Macan, 911 | Cayenne, Panamera | ||
| RENAULT | Clio, Logan, Megane, Sandero, Symbol | Fluence, Kangoo, Latitude, Laguna, Scenic, Duster, Koleos | ||
| ROLLS-ROYCE | Ghost, Phantom, Wraith | |||
| SAAB | 900, 9-3 | 9000, 9-5 | ||
| SEAT | Ibiza, Leon | Altea Freetrack, Alhambra | ||
| SKODA | Fabia, Rapid | Roomster, Superb, Yeti, Karoq, Octavia | Kodiaq | |
| SUBARU | Impreza, XV | BRZ, Legacy, Forester, Outback | Tribeca | |
| SUZUKI | Splash, Liana, SX4, Swift | Kizashi, Grand Vitara | ||
| TOYOTA | Yaris, Auris, Corolla, Prius, Verso | Avensis, Camry, GT, RAV-4, Venza | LC Prado, Highlander | Alphard, LC200, LC300, Hiace, Sequoia, Tundra |
| VOLKSWAGEN | Lupo, Beattle, Bora, Golf, Polo, Sirocco, Jetta | Caddy, CC, Passat, Touran, Tiguan | Phaeton, Sharan, Touareg | Amarock, California, Multivan, Crafter |
| VOLVO | C30, C70, S40, | S60, S80, V40, XC60, XC70 | XC90 | |
| VAZ | Oka, Vesta, Granta, Kalina, Priora, 110-112, 2101-21099 | Largus, X-RAY, Niva, 2120 |
Классификация авто с пробегом
01 июля 2022
У каждого транспортного средства своя индивидуальная жизнь, и состояние любого автомобиля определяется огромным количеством факторов. Для того, чтобы было проще ориентироваться, мы создали классификацию автомобилей с пробегом.
Для того, чтобы было проще ориентироваться, мы создали классификацию автомобилей с пробегом.
В зависимости от результатов диагностики автомобилю присваивается одна из категорий, характеризующая его техническое состояние. Допустимо присутствие не более двух пунктов из более низкой категории (не касается пунктов из последней категории).
Узнайте больше про автомобили с пробегом по телефону: +7 (4912) 460-760 или 701-930.
Мы находимся по адресу: г. Рязань, Московское шоссе, 12а.
Время работы: ежедневно с 09:00 до 21:00
Категория ADVICE (A)
- Возраст автомобиля (с даты первой регистрации): не более 5 лет
- Пробег: не более 75 000 км
- ТО: до ТО не менее 3 000 км, индикация ТО не горит
- Салон: элементы и детали интерьера салона не имеют повреждений и потертостей, посторонние запахи в салоне отсутствуют, не допускается наличие прожженных элементов интерьера салона
- ПТС: оригинал
- Количество владельцев: не более 2-х
- Кузов и диски: мелкие царапины и потертости ЛКП и колесных дисков не до “грунта”
- История: автомобиль не принимал участия в ДТП с нарушением геометрических параметров кузова/рамы
- Двигатель: работает в штатном режиме
- КПП: работает в штатном режиме
- Тормозная система: работает в штатном режиме
- Рулевое управление: работает в штатном режиме
- Электрооборудование: работает в штатном режиме
- Подвеска: работает в штатном режиме
Категория BASE (B)
- Возраст автомобиля (с даты первой регистрации): не более 10 лет
- Пробег: не более 150 000 км
- ТО: до ТО не менее 3 000 км, индикация ТО не горит
- Салон: на элементах интерьера допустимы царапины, потертости и механические повреждения, не требующие замену детали
- ПТС: оригинал/дубликат
- Кузов и диски: на ЛКП допустимы сколы, царапины, не устраняемые полировкой, незначительное число царапин до грунта, пластика или металла, незначительные повреждения кузовных деталей, следы поверхностной коррозии; отсутствуют визуально заметные крупные царапины, значительные кузовные повреждения, следы сквозной коррозии; вмятины, если они не превышают 10см в диаметре без повреждения лакокрасочного покрытия при условии не больше трех вмятин на автомобиле в целом
- История: автомобиль не принимал участия в ДТП с нарушением геометрических параметров кузова/рамы
- Двигатель: работает в штатном режиме
- КПП: работает в штатном режиме
- Тормозная система: работает в штатном режиме
- Рулевое управление: работает в штатном режиме
- Электрооборудование: работает в штатном режиме
- Подвеска: работает в штатном режиме
Категория COMPROMISE (C)
- Возраст автомобиля (с даты первой регистрации): не влияет
- Пробег: более 150 000 км
- Салон: допустимы повреждения обивки сидений, потолка, консоли, рычага коробки передач, обшивки дверей, следы, оставшиеся от пепла сигарет (прожоги)
- ПТС: оригинал/дубликат
- Кузов и диски: допустимы вмятины и повреждения колесных дисков, сквозная коррозия ЛКП, следы некачественного восстановительного ремонта, следы нарушения геометрии кузова
- История: автомобиль мог принимать участие в ДТП с нарушением геометрических параметров кузова / рамы
- Двигатель: работает в штатном режиме
- КПП: работает в штатном режиме
- Тормозная система: работает в штатном режиме (если иное не прописано в сертификате контроля)
- Рулевое управление: работает в штатном режиме
- Электрооборудование: работает в штатном режиме (если иное не прописано в сертификате контроля)
- Подвеска: работает в штатном режиме (если иное не прописано в сертификате контроля)
Категория «Z»
- Возраст автомобиля (с даты первой регистрации): не влияет
- Пробег подлинность пробега: не установлена
- Салон: допустимы повреждения, порезы обивки сидений, потолка, консоли, рычага коробки передач, обшивки дверей, следы, оставшиеся от пепла сигарет (прожоги), наличие большого количества или больших ярко выраженных пятен
- ПТС: оригинал/дубликат
- Кузов и диски: допустимы вмятины и повреждения колесных дисков, сквозная коррозия ЛКП, следы не качественного восстановительного ремонта, следы нарушения геометрии кузова
- История: автомобиль мог принимать участие в ДТП с нарушением геометрических параметров кузова/рамы
- Двигатель: может требовать ремонта
- КПП: может требовать ремонта
- Тормозная система: может требовать ремонта
- Рулевое управление: может требовать ремонта
- Подвеска: может требовать ремонта
Найти автомобиль
Вверх
Trade-in оценка
Связаться с дилером
Автоклассификатор | Метаданные | Поисковые технологии
Организации уже давно пытаются сделать активы знаний доступными для сотрудников, партнеров и клиентов. Несмотря на то, что за последние два десятилетия были достигнуты значительные технологические достижения в области сбора и предоставления этой информации, в основном они были связаны с одним бизнес-процессом. Например, когда я присоединился к Servicesoft, мы впервые предложили использовать поисковые и классификационные механизмы для передачи информации клиентам в рамках развивающегося рынка электронных услуг. В OutStart мы выдвинули идею объективизации обучения и разработки компонентов обучения, чтобы их можно было использовать с помощью модели «точно вовремя». Это означало, что учащиеся взаимодействовали только с объектами обучения, которые помогали им увеличивать свои знания и, следовательно, свою ценность для организации. В последнее десятилетие появилось еще одно хранилище для сбора информации в виде программного обеспечения для социального бизнеса, которое упрощает сбор крупиц знаний, которые могут помочь другим. Интересная динамика во всем этом заключается в том, что для сбора информации и активов знаний делаются большие инвестиции, но на самом деле очень немногие из них доступны для сотрудников или клиентов.
Несмотря на то, что за последние два десятилетия были достигнуты значительные технологические достижения в области сбора и предоставления этой информации, в основном они были связаны с одним бизнес-процессом. Например, когда я присоединился к Servicesoft, мы впервые предложили использовать поисковые и классификационные механизмы для передачи информации клиентам в рамках развивающегося рынка электронных услуг. В OutStart мы выдвинули идею объективизации обучения и разработки компонентов обучения, чтобы их можно было использовать с помощью модели «точно вовремя». Это означало, что учащиеся взаимодействовали только с объектами обучения, которые помогали им увеличивать свои знания и, следовательно, свою ценность для организации. В последнее десятилетие появилось еще одно хранилище для сбора информации в виде программного обеспечения для социального бизнеса, которое упрощает сбор крупиц знаний, которые могут помочь другим. Интересная динамика во всем этом заключается в том, что для сбора информации и активов знаний делаются большие инвестиции, но на самом деле очень немногие из них доступны для сотрудников или клиентов.
В 90-х годах несколько поставщиков программного обеспечения пытались решить проблему доступа к информации, предоставляя программное обеспечение для реализации порталов, независимо от того, использовались ли они для интеграции службы поддержки, поддержки клиентов, интрасетей или исследований и разработок, чтобы помочь в совместной работе и повторном использовании IP. По мере развития технологий и появления поисковых систем и устройств порталы были заменены реализациями корпоративного поиска. Проблема с этим подходом заключается в том, что он рассматривает поисковую систему как универсальное решение, а не как вспомогательную технологию, которая помогает организациям решать бизнес-задачи. Неудачные проекты корпоративного поиска стали нормой, поскольку компании пытались и продолжают пытаться решить свои проблемы с доступом к информации путем внедрения новых поисковых устройств, в то время как у них все еще есть основные проблемы, связанные с интеграцией с другими системами, классификацией и тегами, а также неудовлетворительным пользовательским интерфейсом.
Я присоединился к BA Insight, потому что увидел огромную возможность изменить способ реализации корпоративного поиска. Я уверен, вы знаете, что объем создаваемого контента экспоненциально растет из все большего числа источников, и неспособность найти информационные активы, в которых нуждаются наши люди, обходится нам в миллиарды долларов в виде потери производительности, а также ведет к снижению морального духа и неудовлетворенность клиентов.
Когда я оценивал возможности в BA Insight, я обнаружил, что компания находится в уникальном положении, чтобы предложить новый подход к объединению информации, который остановит шаблон неудач корпоративного поиска. Мы делаем это, превращая SharePoint, который стал повсеместным на предприятиях, в унифицированную платформу доступа к информации, которая позволяет быстро внедрять ориентированные на поиск приложения за небольшую часть стоимости других вариантов, снижая при этом риски проектов поиска.
В Потребительском Интернете доступно множество известных и успешных поисковых приложений. Многие из них являются «убийственными приложениями», и как класс они коренным образом изменили то, как люди взаимодействуют с информацией. Однако, по сравнению с ними, корпоративные интранеты, порталы поддержки клиентов, приложения службы поддержки или решения для управления знаниями и близко не подходят к числу «киллер-приложений» и не обеспечивают выдающегося пользовательского опыта.
Многие из них являются «убийственными приложениями», и как класс они коренным образом изменили то, как люди взаимодействуют с информацией. Однако, по сравнению с ними, корпоративные интранеты, порталы поддержки клиентов, приложения службы поддержки или решения для управления знаниями и близко не подходят к числу «киллер-приложений» и не обеспечивают выдающегося пользовательского опыта.
Меня заинтриговало, что у BA Insight есть технологии, люди и партнеры, которые помогут вывести корпоративный поиск на новый уровень. Мы заменяем подход с интенсивным использованием людей, ориентированный на SI, на подход, основанный на технологиях, который является более дешевым, с меньшим риском, более простым в реализации и более легком обновлении. Мы делаем все возможное, чтобы наши продукты работали с различными версиями SharePoint, а также с различными версиями других программных приложений, существующих в инфраструктуре клиента. Мы автоматизируем процесс пометки контента, чтобы упростить его поиск, а также предоставляем готовые возможности для улучшения взаимодействия пользователей с поиском информации и доступом к ней.
Я считаю, что для того, чтобы компания добилась невероятного успеха, она должна демонстрировать следующие пять важных качеств:
Первый – клиентоориентированность. Клиенты доверяют стартапам с видением, и мы должны сотрудничать с ними, чтобы обеспечить их успех. Я так горжусь всеми клиентами, которых я имел честь обслуживать, а также их достижениями, и я считаю это краеугольным камнем моего прошлого успеха и будущего успеха BA Insight.
Второй это наша команда. У наших сотрудников есть опыт и желание помочь нашим клиентам внедрять и развертывать невероятно мощные приложения. Мы хотим помочь нашим клиентам создавать потрясающие приложения, а не поисковые порталы. Это команда энергичных, преданных своему делу, ориентированных на клиента экспертов, которые пришли к выводу, что приложения, ориентированные на поиск, могут быть намного лучше, и работают над изменением способа их внедрения. Мне посчастливилось стать частью команды BA Insight, и я очень горжусь всеми, кто здесь работает. За короткий период времени мы добились невероятного прогресса во многих областях, и я твердо уверен, что всеобщая лояльность и вера в компанию будут и впредь придавать нам невероятную глубину и помогать нашим клиентам изменить то, как они работают с поисковыми технологиями.
За короткий период времени мы добились невероятного прогресса во многих областях, и я твердо уверен, что всеобщая лояльность и вера в компанию будут и впредь придавать нам невероятную глубину и помогать нашим клиентам изменить то, как они работают с поисковыми технологиями.
Третий это технология. У нас есть широкий набор возможностей, которые расширяют ценность существующих инвестиций в SharePoint, поэтому мы избавляемся от необходимости изменять базовую инфраструктуру, экономя много времени и денег. У нас есть более 90 готовых коннекторов, механизм автоматической пометки мирового класса для контента внутри и вне SharePoint, визуальные уточнения, позволяющие пользователям быстро находить информацию и детализировать ее, активное рабочее пространство с возможностью сборки контента и возможностями предварительного просмотра документов. Мы также предоставляем большую гибкость в том, как наша технология может быть реализована. Например, наша полная платформа особенно хорошо подходит для новых проектов. С другой стороны, если в организации уже внедрены поисковые приложения, то компоненты нашей платформы можно использовать для расширения существующей технологии для улучшения результатов.
С другой стороны, если в организации уже внедрены поисковые приложения, то компоненты нашей платформы можно использовать для расширения существующей технологии для улучшения результатов.
Четвертый должен нести финансовую ответственность. Успех компании зависит от инвестиций и отдачи от этих инвестиций, и его необходимо измерять по двум направлениям:
- ROI, который представляет собой чисто количественный и финансовый анализ, часто измеряемый как прирост производительности.
- Я предпочитаю подход с окупаемостью (ROV), который является качественным и фокусируется на таких аспектах, как лояльность клиентов, моральный дух сотрудников, более эффективное принятие решений и способность быстрее находить информацию для повышения скорости реагирования клиентов. Многие из этих вещей влияют на производительность и, следовательно, являются рентабельностью инвестиций, но они не часто измеряются, и поэтому их трудно определить количественно.
 Разве получение нужных знаний для выполнения своей работы не бесценно? Если мы разумно инвестируем наше время, деньги и энергию на основе окупаемости, то мы естественным образом приносим огромную пользу нашим клиентам и рынку и в конечном итоге становимся растущей, прибыльной компанией, устойчивой к взлетам и падениям. экономики и рынка.
Разве получение нужных знаний для выполнения своей работы не бесценно? Если мы разумно инвестируем наше время, деньги и энергию на основе окупаемости, то мы естественным образом приносим огромную пользу нашим клиентам и рынку и в конечном итоге становимся растущей, прибыльной компанией, устойчивой к взлетам и падениям. экономики и рынка.
 Разве получение нужных знаний для выполнения своей работы не бесценно? Если мы разумно инвестируем наше время, деньги и энергию на основе окупаемости, то мы естественным образом приносим огромную пользу нашим клиентам и рынку и в конечном итоге становимся растущей, прибыльной компанией, устойчивой к взлетам и падениям. экономики и рынка.
Разве получение нужных знаний для выполнения своей работы не бесценно? Если мы разумно инвестируем наше время, деньги и энергию на основе окупаемости, то мы естественным образом приносим огромную пользу нашим клиентам и рынку и в конечном итоге становимся растущей, прибыльной компанией, устойчивой к взлетам и падениям. экономики и рынка.И пятый способствует сохранению баланса между работой и личной жизнью. Работа важна, но мы не можем забывать о своих семьях и не должны ставить под угрозу общение с ними из-за загруженности офиса. Долгое время я был трудоголиком, но после рождения первого сына решил измениться. На протяжении многих лет я делал все возможное, чтобы практиковать то, что проповедую, успешно совмещая работу и семейную жизнь, и призываю наших сотрудников делать то же самое. Я не получаю ничего, кроме как проводить время с моей невероятной женой и нашими замечательными мальчиками.
Эти качества преобладают в BA Insight, и я с большим энтузиазмом отношусь к возможностям, которые открываются впереди. Я абсолютно уверен, что у нас хорошие позиции для обеспечения будущего унифицированного доступа к информации, поскольку мы помогаем дальновидным организациям по всему миру осознать ценность коллективного разума, который каждый день фиксируется в огромных объемах контента, который они производят.
Я абсолютно уверен, что у нас хорошие позиции для обеспечения будущего унифицированного доступа к информации, поскольку мы помогаем дальновидным организациям по всему миру осознать ценность коллективного разума, который каждый день фиксируется в огромных объемах контента, который они производят.
Ускорьте свои модели машинного обучения с помощью AutoML
Эта статья была опубликована в рамках блога Data Science Blogathon.
Введение
AutoML — это относительно новое и развивающееся подмножество машинного обучения. Основной подход в AutoML заключается в том, чтобы ограничить участие специалистов по данным и позволить инструменту обрабатывать все трудоемкие процессы машинного обучения, такие как предварительная обработка данных, выбор наилучшего алгоритма, настройка гиперпараметров и т. д., что экономит время на настройку этих моделей машинного обучения и ускорение их развертывания. В настоящее время на рынке доступно несколько инструментов AutoML.
В одной из моих предыдущих статей в блоге я поделился исчерпывающим руководством по AutoML с простым примером AutoGluon. В это руководство включен список нескольких инструментов AutoML, доступных в настоящее время на рынке. Эти инструменты AutoML, несомненно, могут сэкономить много времени, особенно для больших и сложных наборов данных. В этой статье мы рассмотрим один такой инструмент под названием «Auto-Sklearn».
В это руководство включен список нескольких инструментов AutoML, доступных в настоящее время на рынке. Эти инструменты AutoML, несомненно, могут сэкономить много времени, особенно для больших и сложных наборов данных. В этой статье мы рассмотрим один такой инструмент под названием «Auto-Sklearn».
Что такое Auto-Sklearn?
Любой, кто знаком с машинным обучением, знает о scikit-learn, известном пакете Python, состоящем из различных алгоритмов классификации и регрессии и используемом для построения моделей машинного обучения.
Auto-Sklearn — это набор инструментов с открытым исходным кодом на основе Python для выполнения AutoML. Он использует известный пакет машинного обучения Scikit-Learn для обработки данных и алгоритмов машинного обучения. Он также включает метод поиска байесовской оптимизации, чтобы быстро найти лучший конвейер модели для данного набора данных. В этой статье мы рассмотрим, как использовать Auto-Sklearn для задач классификации и регрессии.
Давайте сначала установим пакет Auto-Sklearn.
pip установить авто-sklearn
(Если вы используете Google Colab, убедитесь, что у вас самая последняя версия SciPy; в противном случае обновите ее с помощью команды pip и перезапустите среду выполнения)
pip install --upgrade scipy
Теперь, когда мы установили инструмент AutoML, мы импортируем основные пакеты для предварительной обработки набора данных и визуализации.
импортировать панд как pd импортировать numpy как np импортировать matplotlib.pyplot как plt импортировать Seaborn как sns из sklearn.model_selection импорта train_test_split
Задача классификации
Мы будем использовать набор данных для прогнозирования сердечных заболеваний, доступный в репозитории UCI. Для удобства воспользуемся CSV-версией этих данных из Kaggle. Вы также можете использовать любой набор данных классификации по вашему выбору или импортировать игрушечный набор данных, доступный из библиотеки sklearn.
Сведения о наборе данных: Этот набор данных содержит 303 выборки и 14 атрибутов (исходный набор данных содержит 76 объектов, а версия . csv содержит 14 подмножеств исходного набора данных).
csv содержит 14 подмножеств исходного набора данных).
Импорт набора данных и печать первых нескольких строк
дф=pd.read_csv('/content/heart.csv')
дф.голова() Давайте проверим целевую переменную target в наборе данных
дф['цель'].value_counts()
Существует только два класса (0=здоровые, 1=сердечно-сосудистые заболевания), так что это проблема бинарной классификации. Кроме того, это указывает на то, что это несбалансированный набор данных. Из-за этого оценка точности этой модели будет менее надежной. Однако сначала мы проверим несбалансированный набор данных, напрямую передав его классификатору autosklearn. Позже мы настроим количество выборок для этих двух классов и проверим точность, чтобы увидеть, как работает классификатор.
#создание X и Y X=df.drop(['цель'],ось=1) у=дф['цель']
# разделить на наборы поездов и тестов X_train, X_test, y_train, y_test= train_test_split(X,y, test_size=0,2, random_state=42) X_train.
 shape, X_test.shape, y_train.shape, y_test.shape
shape, X_test.shape, y_train.shape, y_test.shape Далее мы импортируем модели классификации из autosklearn с помощью следующей команды.
импортировать autosklearn.classification
Затем мы создадим экземпляр AutoSklearnClassifier для задачи классификации.
automl = autosklearn.classification.AutoSklearnClassifier(time_left_for_this_task=5*60,per_run_time_limit=30,tmp_folder='/temp/autosklearn_classification_example_tmp')
Здесь мы устанавливаем максимальное время для этой задачи с помощью аргумента «time_left_for_this_task» и назначаем ей 5*60 секунд или 5 минут. Если для этого аргумента ничего не указано, процесс будет выполняться в течение часа, т. е. 60 минут. Затем мы также установим время, отведенное на 30 секунд для каждой оценки модели, используя « per_run_time_limit ” аргумент.
В этой команде есть и другие аргументы, такие как n_jobs (количество параллельных заданий), ансамбль_размер, initial_configurations_via_metalearning, которые можно использовать для тонкой настройки классификатора. По умолчанию приведенная выше команда поиска создает ансамбль наиболее эффективных моделей. Чтобы избежать переобучения, мы можем отключить его, изменив настройку « ансамбль_размер » = 1 и « начальные_конфигурации_через_металлическое обучение » = 0. Мы исключили их при настройке классификатора, чтобы сделать учебник простым.
По умолчанию приведенная выше команда поиска создает ансамбль наиболее эффективных моделей. Чтобы избежать переобучения, мы можем отключить его, изменив настройку « ансамбль_размер » = 1 и « начальные_конфигурации_через_металлическое обучение » = 0. Мы исключили их при настройке классификатора, чтобы сделать учебник простым.
Мы также предоставим временный путь для сохранения журнала, и мы сможем использовать его для печати сведений о запуске позже.
Теперь подгоним классификатор.
automl.fit(X_train, y_train)
Функция sprint_statistics() суммирует вышеуказанный поиск и производительность выбранной лучшей модели.
pprint(automl.sprint_statistics())
Кроме того, мы также можем распечатать таблицу лидеров для всех моделей, рассмотренных в результате поиска, организованных по их рангам, используя следующую команду.
печать (automl.leaderboard())
Две лучшие модели, выбранные классификатором, были Random forest и Passive_aggressive соответственно.
Дополнительно мы можем распечатать информацию о рассматриваемых моделях с помощью следующей команды:
pprint(automl.show_models())
Наконец, мы также можем распечатать окончательную оценку ансамбля и матрицу путаницы, используя следующие строки кода.
# Партитура финального ансамбля из sklearn.metrics импорта precision_score m1_acc_score= показатель_точности (y_test, y_pred) m1_acc_score
из sklearn.metrics импорта путаница_матрица, точность_оценка y_pred = automl.predict (X_test)
conf_matrix = матрица_замешательства (y_pred, y_test) sns.heatmap(conf_matrix, annot=True)
Мы можем использовать следующую команду для разделения здоровых и нездоровых образцов в наборе данных.
из sklearn.utils импортировать повторную выборку здоровый = df[df["цель"]==0] нездоровый=df[df["цель"]==1]
По мере того, как количество нездоровых выборок будет больше, мы воспользуемся техникой передискретизации (перевыборки) и увеличим выборки здоровых людей в наборе данных.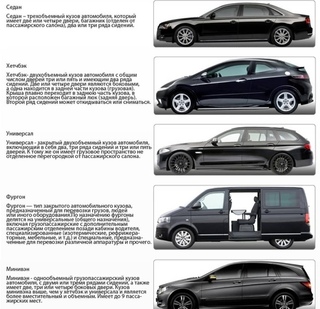 Чтобы настроить перекос, мы можем использовать следующие команды —
Чтобы настроить перекос, мы можем использовать следующие команды —
up_sampled=resample(исправен, replace=True, n_samples=len(неисправен), random_state=42) up_sampled=pd.concat([нездоровый, up_sampled])
#check обновленное количество классов up_sampled['target'].value_counts()
Мы также можем использовать такие методы, как SMOTE, обучение ансамблю (пакетирование, повышение), алгоритм NearMiss для устранения дисбаланса в наборе данных. Кроме того, мы можем использовать такие показатели, как оценка F1, точность и полнота, чтобы оценить производительность модели.
Теперь, когда мы скорректировали перекос, мы снова создадим наборы X и Y для классификации. Назовем их X1 и y1, чтобы избежать путаницы.
X1=up_sampled.drop(['цель'],ось=1) y1=up_sampled['цель']
Нам нужно повторить все шаги от настройки классификатора до печати матрицы путаницы для этих новых X1 и y1. Полный код для этой задачи доступен в моем репозитории GitHub.
Наконец, мы можем сравнить две точности для искаженных данных и скорректированных данных, используя –
model_eval = pd.DataFrame({'Модель': ['перекос','скорректированный'], 'Точность': [m1_acc_score,m2_acc_score]})
model_eval = model_eval.set_index('Модель').sort_values(по = 'Точность', по возрастанию = Ложь)
рис = plt.figure(figsize=(12, 4))
gs = fig.add_gridspec(1, 2)
gs.update(wspace=0.8, hspace=0.8)
ax0 = fig.add_subplot (gs [0, 0])
sns.heatmap(model_eval,cmap="PiYG",annot=True,fmt=".1%", linewidths=4,cbar=False,ax=ax0)
plt.show() На приведенном выше графике точность модели немного снизилась после передискретизации, мы видим, что теперь модель лучше оптимизирована. Хотя мы использовали довольно много дополнительных команд для предварительной обработки данных и оценки результатов, для запуска классификатора AutoSklearn требуется всего одна строка кода. Даже с искаженными данными точность, достигнутая моделью, действительно хороша.
Задача регрессии
Теперь в этом разделе мы будем использовать модели регрессии от AutoSklearn.
Для этой задачи воспользуемся простым набором данных «рейсы» из библиотеки наборов морских данных. Мы загрузим набор данных с помощью следующей команды.
# загрузка набора данных
df = sns.load_dataset('рейсы')
дф.голова()
Детали набора данных: Этот набор данных содержит 144 строки и 3 столбца, а именно год, месяц и количество пассажиров.
Задача здесь состоит в том, чтобы предсказать количество пассажиров, используя два других признака.
X=df.drop(["пассажиры"],ось=1) y=df["пассажиры"] X.форма, у.форма
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0,2, random_state=42) X_train.shape, X_test.shape, y_train.shape, y_test.shape
Теперь мы используем autosklearnregressor для этой задачи регрессии.
импортировать autosklearn.regression automl = autosklearn.regression.AutoSklearnRegressor( time_left_for_this_task=5*60,per_run_time_limit=30,tmp_folder='/temp/autosklearn_regression_example_tmp')
automl.
 fit(X_train, y_train)
из sklearn.metrics импорта mean_absolute_error
из autosklearn.metrics импортировать mean_absolute_error как auto_mean_absolute_error
fit(X_train, y_train)
из sklearn.metrics импорта mean_absolute_error
из autosklearn.metrics импортировать mean_absolute_error как auto_mean_absolute_error Теперь напечатаем статистику модели.
# суммировать печать (automl.sprint_statistics ())
Из напечатанного выше резюме мы понимаем, что регрессор прогнал в общей сложности 59 моделей, а расчетная производительность окончательной регрессионной модели составила R2 0,985, что довольно хорошо.
Поскольку регрессор по умолчанию оптимизировал метрику R2, давайте напечатаем среднюю абсолютную ошибку, чтобы лучше оценить производительность модели.
# оценить лучшую модель
y_pred = automl.predict(X_test)
mae = средняя_абсолютная_ошибка (y_test, y_pred)
print("MAE: %.3f" % mae) Средняя абсолютная ошибка приемлема, учитывая значение R2, достигнутое моделью, и размер набора данных, используемого в качестве примера для этой задачи.
Мы также можем построить график предсказанных значений против фактических значений, используя matplotlib, как показано ниже.
plt.figure(figsize=(8,6))
plt.scatter(y_test, y_pred, c='синий')
p1 = макс (макс (у_пред), макс (у_тест))
p2 = мин (мин (у_пред), мин (у_тест))
plt.plot([p1, p2], [p1, p2], 'r-')
plt.xlabel('Фактическое', размер шрифта=10)
plt.ylabel («Прогноз», размер шрифта = 10)
plt.legend(['Фактическое', 'Прогнозируемое'])
плт.ось('равно')
plt.show() В целом, мы можем сказать, что значение MAE невелико, и модель получила высокую оценку проверки — 0,985, что указывает на хорошую производительность модели.
Сохранение обученных моделей.
Обученные выше модели для классификации и регрессии можно сохранить с помощью пакетов Python Pickle и JobLib. Эти сохраненные модели затем можно использовать для прогнозирования непосредственно на основе новых данных. Мы можем сохранить модели как:
1. Использование рассола
импортный рассол # сохранить модель имя файла = 'final_model.sav' pickle.dump(модель, открыть(имя файла, 'wb'))
Здесь аргумент wb означает, что мы записываем файл на диск в бинарном режиме. Далее мы можем загрузить эту сохраненную модель как:
Далее мы можем загрузить эту сохраненную модель как:
#загрузить модель загруженная_модель = pickle.load (открыть (имя файла, 'rb')) результат = загруженная_модель.score (X_test, Y_test) печать (результат)
Здесь команда «rb» указывает, что мы читаем файл в двоичном режиме.
2. Использование
JobLib
Точно так же мы можем сохранить обученные модели в JobLib, используя следующую команду.
импортировать библиотеку заданий # сохранить модель имя файла = 'final_model.sav' joblib.dump(модель, имя файла)
Мы также можем перезагрузить эти сохраненные модели позже для прогнозов на основе новых данных.
# загрузить модель с диска load_model = joblib.load(имя файла) результат = load_model.score (X_test, Y_test) печать (результат)
Заключение
В этой статье мы увидели применение Auto-Sklearn как для моделей классификации, так и для моделей регрессии. Для обеих задач нам не требовалось указывать конкретный алгоритм.